缓存问题
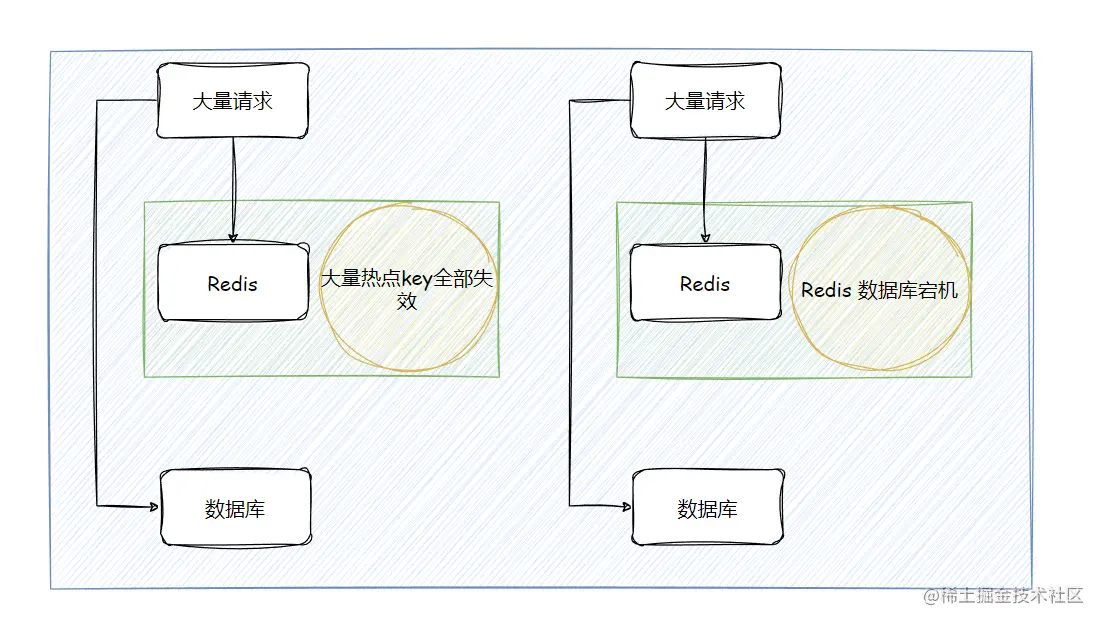
缓存雪崩
同一时间段内大量的热点 key 全部过期或者 Redis 宕机,所有的请求都打到数据库上
解决方法:
- 给不同的 key 添加不同的 TTL ;
- 利用 Redis 集群提高系统的可用性;
- 当系统故障后,可以启动服务熔断机制,暂停业务对外访问,直接返回错误,不让请求访问数据库;
缓存穿透
客户端请求的数据在 Redis 和 数据库 中都不存在,这样的缓存永远不会生效
解决方法:
- 限制非法的请求,对请求的参数作检验
- 缓存空对象或默认值
- 使用布隆过滤器快速判断数据是否存在,避免通过查询数据库判断数据是否存在
布隆过滤器
我们在写入数据库时,在布隆过滤器中做一个标记。业务线程确认缓存失效后,去布隆过滤器中查询该值是否存在,而不用去数据库中进行查询;
即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
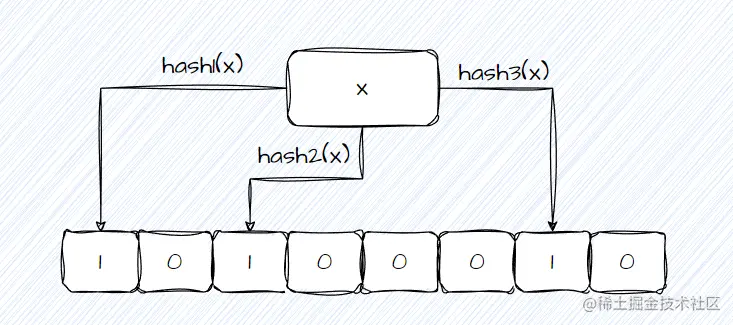
布隆过滤器由三个哈希函数,一个位图数组组成:
- 布隆过滤器先将输入的值通过三个哈希函数得到相应的哈希值;
- 将哈希值对数组的长度取模,进而得到相应的下标;
- 将三个下标设置为1;
判断时,布隆过滤器会读取输入的值,并通过三个哈希函数转化成三个数组下标,然后若三个下标对于值均为1,则该数据存在于布隆过滤器中,若有一个为0,则认为该数据不存在布隆过滤器中;
所以,布隆过滤器说存在数据,但实际上该数据可能不存在,布隆过滤器说不存在该数据,则该数据真的不存在;
缓存击穿
某一个热点 key 过期消失了,大量的请求打到数据库上,数据库很容易被冲垮;
解决方法:
- 使用互斥锁来更新缓存。当某个线程成功获取锁后,进行从数据库中读取最新的数据,并把新数据存入缓存中去即可,而没有获取到锁的线程进行等待或者返回请求失败的响应即可;
- 不给热点数据添加过期值,该 key 由我们手动删除;
- 可以在 value 中添加逻辑过期的字段,一旦超过该时间戳就返回旧的值,再去数据库进行更新;
缓存更新问题
缓存更新策略
| 内存淘汰 | TTL 超时 | 主动更新 | |
|---|---|---|---|
| 说明 | 当Redis内存达到最大值时,我们可以通过 Redis 的内存淘汰策略,淘汰部分的 key | 给每一个key设置过期时间,到达该过期时间后,该 key 会被自动移除 | 通过业务的方法,更新数据库和缓存 |
| 一致性 | 差 | 一般 | 强 |
| 维护成本 | 无 | 一般 | 高 |
主动更新
更新数据库和更新缓存的顺序问题
- 先更新缓存,再更新数据库
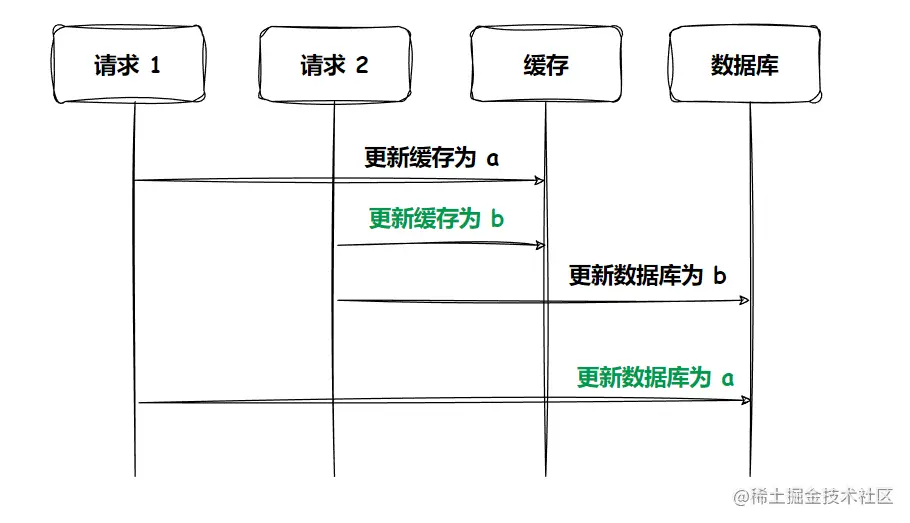
出现了数据的不一致,缓存中的数据为 b,而数据库中的数据为 a
- 先更新数据库,再更新缓存
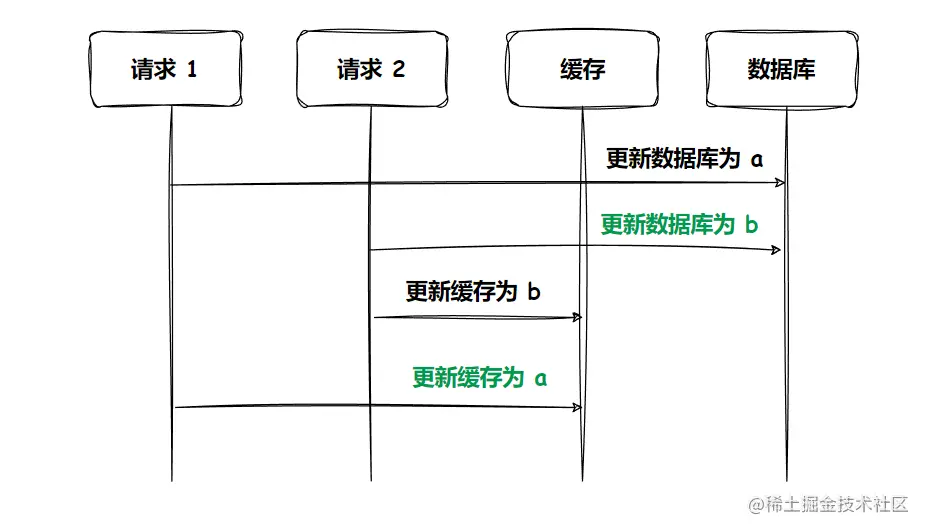
出现了数据的不一致,数据库中的值为 b,而缓存中的值为 a
所以,无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
更新数据库和删除缓存的顺序问题
这里我们更新数据时,不在更新缓存,而是删除缓存,当读取不到缓存时,先从数据库中读取,再写入缓存;这种叫做旁路缓存策略
写操作:
- 更新数据库
- 删除缓存
读操作:
- 如果命中了缓存,直接返回数据
- 如果没有命中缓存,则从数据库读取数据,再写入缓存
- 先删除缓存,再更新数据库
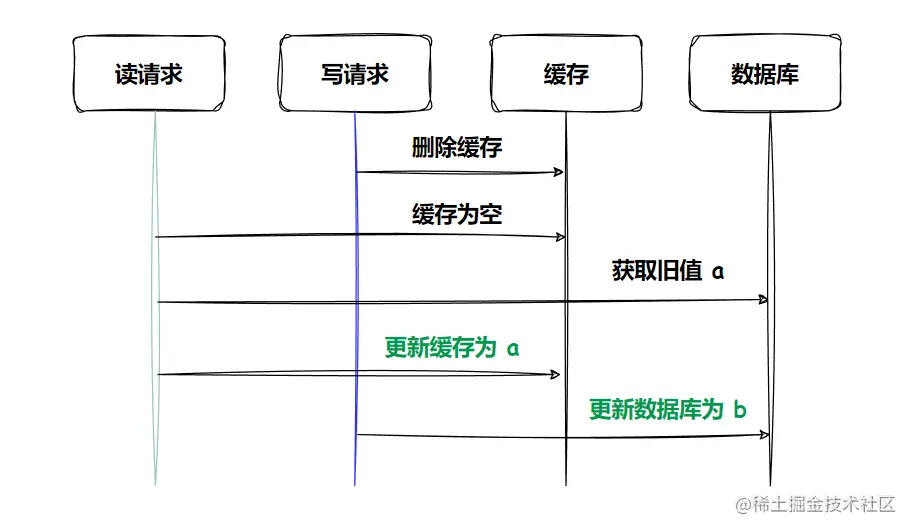
此时也出现了数据的不一致,缓存中的数据为 a,数据库中的数据为 b
- 先更新数据库,再删除缓存
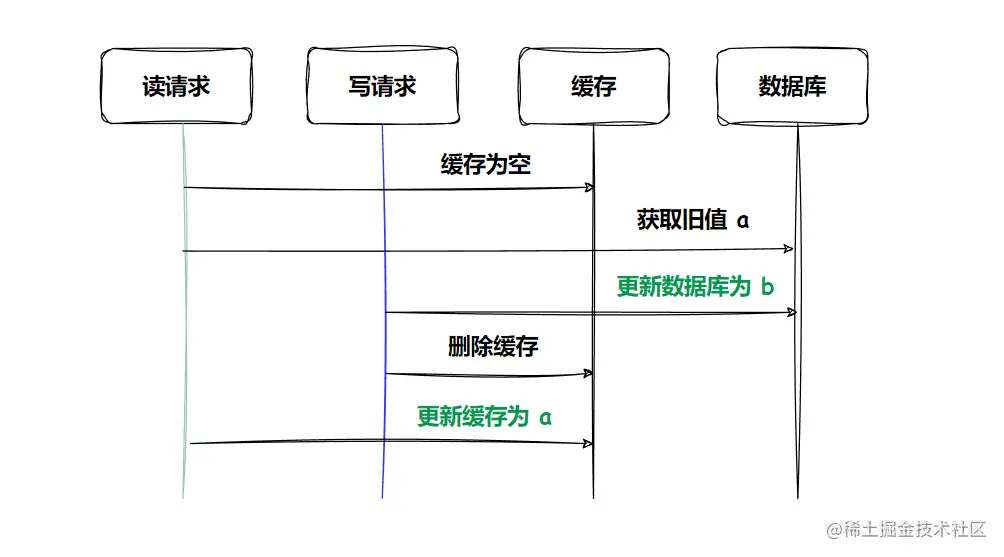
此时也出现了数据的不一致,缓存中的数据为 a,数据库中的数据为 b
但是这种方式出现的几率会很低,因为更新缓存 a 这步操作是在Redis中进行的,更新数据库为 b 的操作是在数据库中进行的,Redis 中的写入操作比 数据库中的写入操作会快很多,所以我们一般采用 更新数据库 + 删除缓存 的手段
如果强制保存缓存为最新值,可以为缓存的 key 设置过期时间,如给 a 设置过期时间,可以作为兜底措施
- 延迟双删,针对 先删除缓存,再更新数据库的情况

伪代码
删除缓存 delete(x) 更新数据 update(x) 睡眠 sleep(N) 再次删除缓存 delete(x)
前提是:睡眠的时间要比读请求的过程要大,保证读请求写入的缓存要在再次删除缓存之前,不然再次删除缓存后还会把旧的值写入缓存






