redis zrange 与 zrangebyscore的区别
前言
想做一个在redis中获取数据时分页的功能,从网上查找到了zrange和zrangebyscore两个函数,对于这两个函数的理解,在刚刚读完官方文档后,还是不太懂:
zrange: “The order of elements is from the lowest to the highest score. Elements with the same score are ordered lexicographically.” https://redis.io/commands/zrange
zrangebyscore:“The elements are considered to be ordered from low to high scores.” https://redis.io/commands/zrangebyscore
嗯?都是依据socre排序,所以啥区别?虽说是一个索引一个score,但结果都是按照score排序,所以到底有啥区别???
刚接触的时候,光靠看定义来理解,真的很容易蒙蔽。
所以做个实验,就清楚了。
先说概念上的结论:
两者的区别,就是一个是“索引”(zrange),一个是“score”(zrangebyscore)!【are you kidding me?!】
实验
数据准备
在redis中依次执行下列语句:
zadd test 1 first zadd test 10 two zadd test 8 three zadd test 7 four zadd test 2 five zadd test 1.1 onePointOne zadd test 2 six zadd test 8 seven zadd test 7 sight
对比案例一
我们输入0 2两个参数来查询(具体命令使用方法请自行查阅官方文档)
用zrange
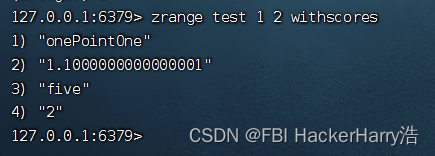
命令:
zrange test 1 2 withscores
结果:
用zrangebyscore
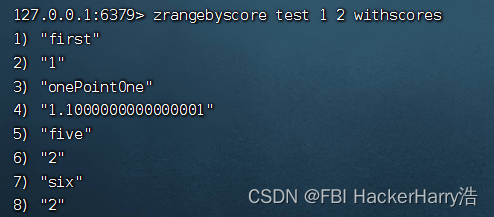
命令
zrangebyscore test 1 2 withscores
结果:
对比结论:
zrange是传入的值是索引 ,因此查询的值“1”代表是查询第二个值,也就是说,索引的情况下,索引0是第一个元素。
而zrangebyscore传入的值就是值本身的含义,也就是“score”
注:确实,官方文档就说了起始值为0的问题,但这确实是一个容易犯错误的地方。
对比案例二
我们输入0 7两个参数来查询(具体命令使用方法请自行查阅官方文档)
用zrange
命令:
zrange test 0 7 withscores
结果:

用zrangebyscore
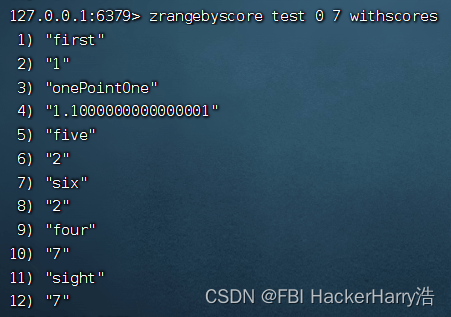
命令:
zrangebyscore test 0 7 withscores
结果:
对比结论:
同上一个测试
zrange查询的结果个数,就是索引的区间长度(如【0-7】,区间长度是8,所以查出来8个数据,当然,前提是数据不少于8个),
而zrangebyscore由于是用socre来查询,因此,在准备的数据中,有多少个符合【0,7】区间的数据,就会返回多少数据。
注:确实,官方文档就说了起始值为0的问题,但这确实是一个容易犯错误的地方。
总结
zrange的第一个数据是索引为0的数据,而zrangebyscore的第一个数据,是score值最小的那个数据
zrange传入的参数是“索引”的含义,而zrangebyscore就是单纯的一个数值的含义
zrange查询的结果个数<= 查询区间长度,也就是说 ,区间多长,就查询出多少个结果出来(数据不少于区间长度,足够多的情况下),而zrangebyscore的查询结果个数视实际数据而定,也就是凡是符合区间的数据,全部查询出来.
所以在分页查询的需求下,zrange可以保证每页的数据量,而zrangebyscore不能保证。
如果有数据更新,zrange就会出现数据查询重复和遗漏的情况。而zrangebyscore却由于符合条件则全部查询出来的特性,而不会出现重复和遗漏。
不理解“重复和遗漏”是怎么发生的?自己仔细思考去吧,实在不行做个实验,你就明白了,这里我不细说。







