哈喽大家好,我是咸鱼
之前咸鱼写过几篇关于知网爬虫的文章,后台反响都很不错。虽然但是,咸鱼还是忍不住想诉苦一下
有些小伙伴文章甚至代码看都没看完,就问我 ”为什么只能爬这么多条文献信息?“(看过代码的会发现我代码里面定义了 papers_need 变量来设置爬取篇数),”为什么爬其他文献不行?我想爬 XXX 文献“(因为代码里面写的是通过【知网高级搜索中的文献来源】来搜索文章),或者是有些小伙伴直接把代码报错贴给我,问我咋回事
我觉得在网上看到别人的代码,不要一昧地拿来主义,复制粘贴就行了,你要结合你自己的本地环境对代码做适当地修改。比如定位 Xpath 元素路径,不通电脑或者说不同浏览器同一元素的 Xpath 路径有可能不是一样的,这个路径在我本地运行没问题,到了你那里就报错
当看别人的代码时,最好先搞清楚:
- 别人是怎么想的
- 别人为什么要这么写
- 这么写的逻辑是什么?
以我这几篇知网爬虫文章举例:
- 为什么要用 selenium 来爬取?
- 如何分析网页?如何定位元素?(Xpath、CSS 选择器等等)
- 如何通过 selenium 来模拟人为操作浏览器(鼠标移动、点击、滑动窗口等等)
言归正传,咸鱼昨天收到一位粉丝私信说能不能根据【关键词】来搜索文献
今天这篇文章着重讲如何分析网页结构然后使用 selenium 根据知网的关键词来搜索文献。至于对搜索到的文献的爬取,本文不过多介绍,因为以前的文章已经写过了
需求分析
我们先来看下如果要通过关键词搜索文献,该怎么操作?
知网:中国知网 (cnki.net)
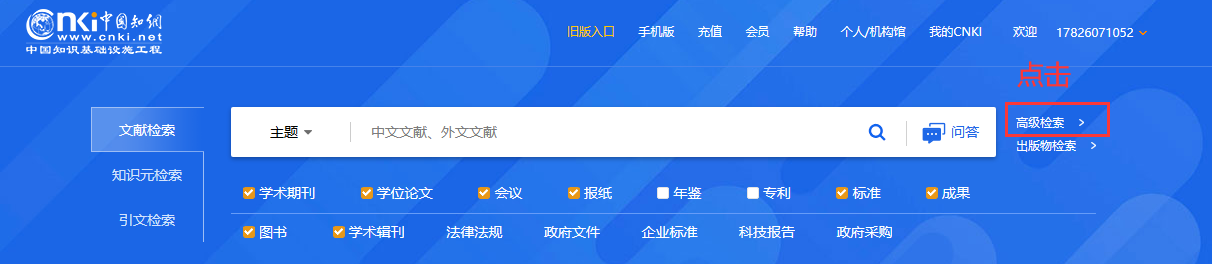
首先我们登录网站,点击【高级搜索】(也可以直接点击搜索框中的【主题】下拉选择)
然后我们点击【主题】——>选择【关键词】
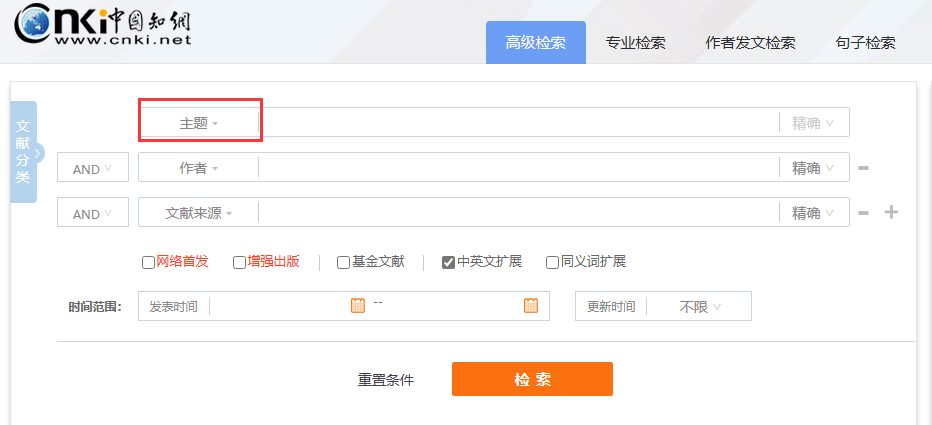
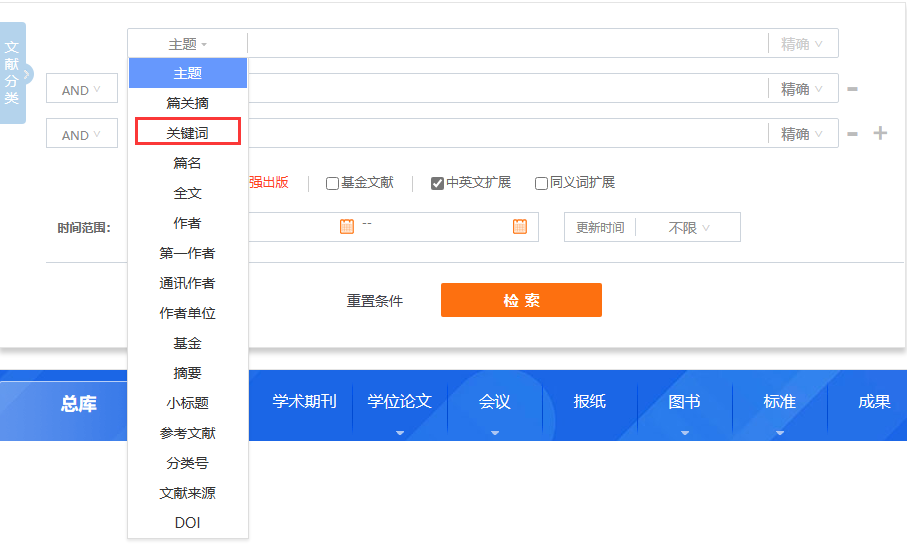
输入要搜索的关键词(例如:数字普惠金融)然后点击【检索】
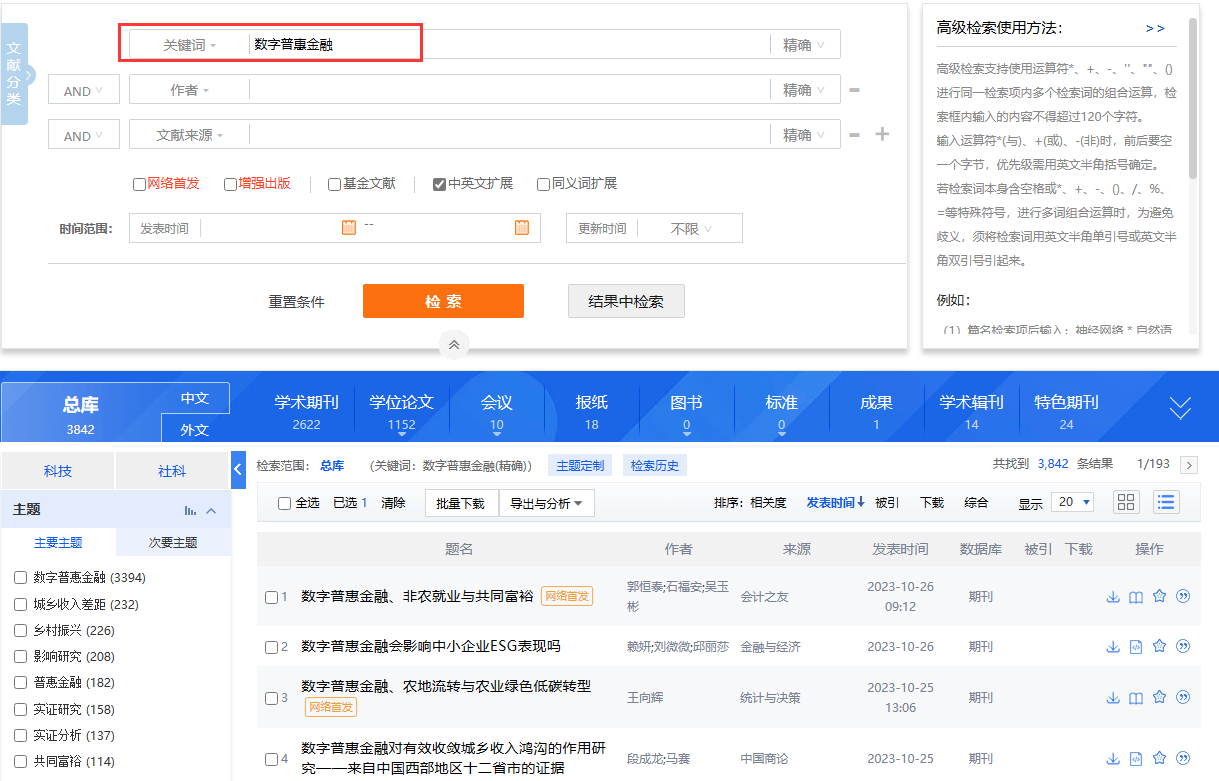
网页分析&元素定位
结合前面的需求分析,我们就可以对网页进行分析并定位出对应的元素
首先是【高级搜索】,高级搜索有一个链接:高级检索-中国知网 (cnki.net),这样就能省掉一个步骤了
然后我们需要点击 【主题】,才会出现下拉框。在分析网页的时候我发现当出现下拉框时,标签 <div class="sort-list" style="display: none;">" 中的 style 属性由 "display: none;" 变成 "display: block;"
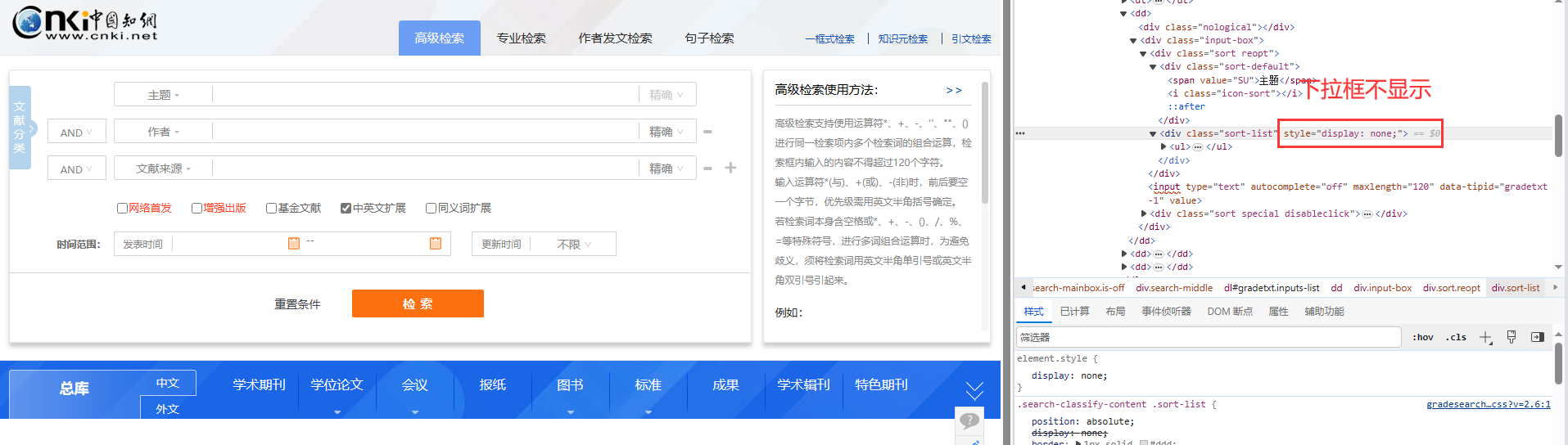
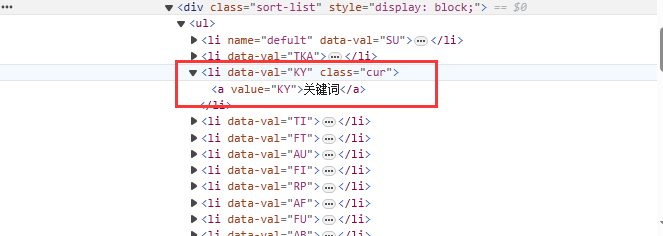
下拉框出现之后,我们需要定位到 【关键词】 这个标签
# 关键词 Xpath 路径或 CSS 选择器
//*[@id="gradetxt"]/dd[1]/div[2]/div[1]/div[2]/ul/li[3]
li[data-val="KY"]
接着找到【搜索框】的 Xpath 路径。这里是一个 input 元素,用于接收来自用户的数据
# 输入框
//*[@id="gradetxt"]/dd[1]/div[2]/input
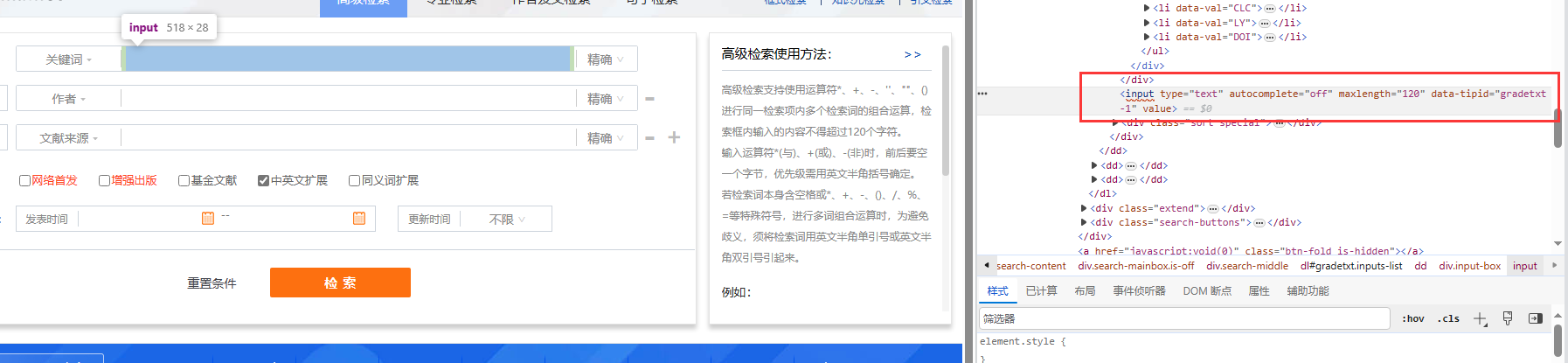
往输入框传入数据之后,我们需要点击下面的【检索】按钮
# 检索
/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input
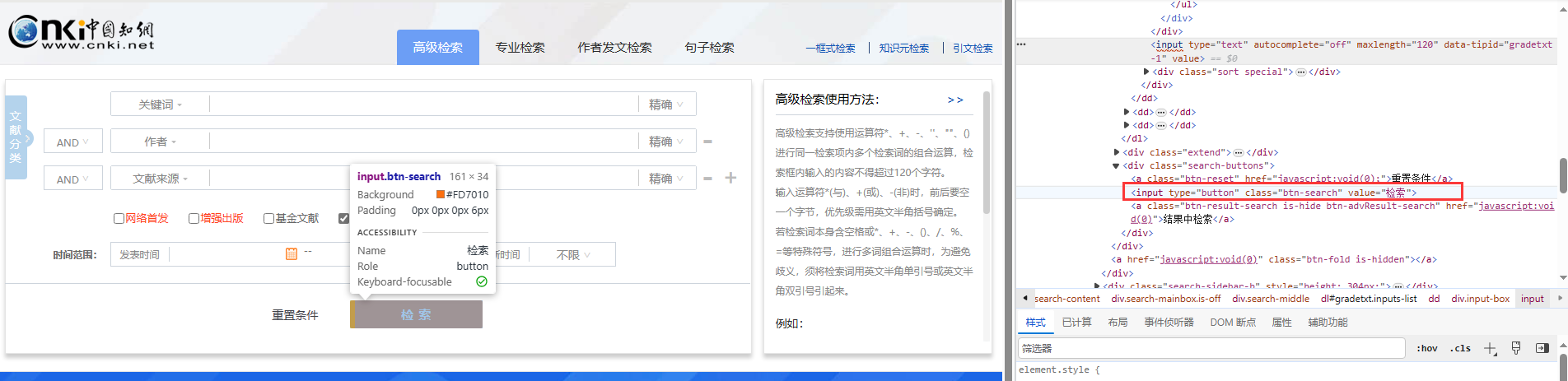
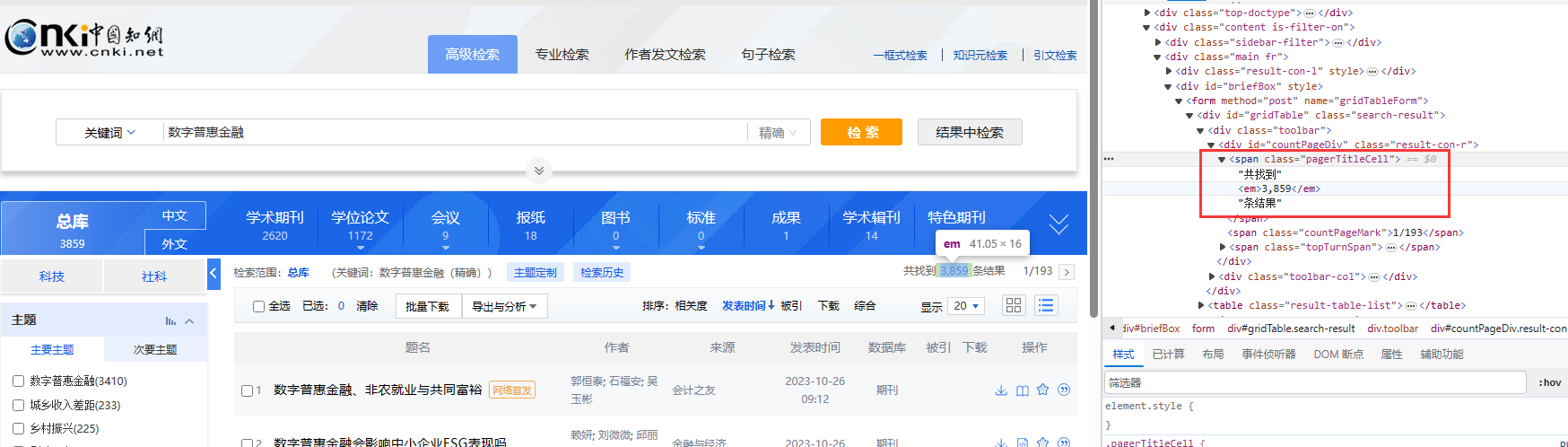
点击搜索之后我们把【文献条数】爬取下来
# 文献条数
/html/body/div[3]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em
代码实现
selenium 是一个自动化测试工具,可以用来进行 web 自动化测试。其本质是通过驱动浏览器,完全模拟浏览器的操作(比如跳转、输入、点击、下拉等)来实现网页渲染之后的结果,可支持多种浏览器
爬虫中用到 selenium 主要是为了解决 requests 无法直接执行 JavaScript 代码等问题
导入相关库
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.action_chains import ActionChains
创建浏览器对象
这里我用的是 Edge 浏览器
def webserver():
# get直接返回,不再等待界面加载完成
desired_capabilities = DesiredCapabilities.EDGE
desired_capabilities["pageLoadStrategy"] = "none"
# 设置微软驱动器的环境
options = webdriver.EdgeOptions()
# 设置浏览器不加载图片,提高加载速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个微软驱动器
driver = webdriver.Edge(options=options)
return driver
爬取网页
其实逻辑并不难,就是先定位到各个元素然后用 selenium 来模拟我们人为点击浏览器的操作就行了
首先打开页面,等待个一两秒让网页完全加载
driver.get("https://kns.cnki.net/kns8/AdvSearch")
time.sleep(2)
然后然下拉框显示出来,前面我们提到:标签 <div class="sort-list" style="display: none;">" 中的 style 属性由 "display: none;" 变成 "display: block;" 时,就会出现下拉框
这里我们通过执行 js 脚本来修改里面的 style 属性
# 修改属性,使下拉框显示
opt = driver.find_element(By.CSS_SELECTOR, 'div.sort-list') # 定位下拉框
# 执行 js 脚本进行属性的修改; arguments[0]代表第一个属性
driver.execute_script("arguments[0].setAttribute('style', 'display: block;')", opt)
下拉框显示出来之后我们需要点击【关键词】,这样才会切换到关键词搜索
这里需要注意的是,当我在测试的时候发现下拉框加载是有问题的,这时候代码会报错说Element <li data-val="KY">...</li> is not clickable at point (189, 249)
就会使得程序点击不了【关键词】
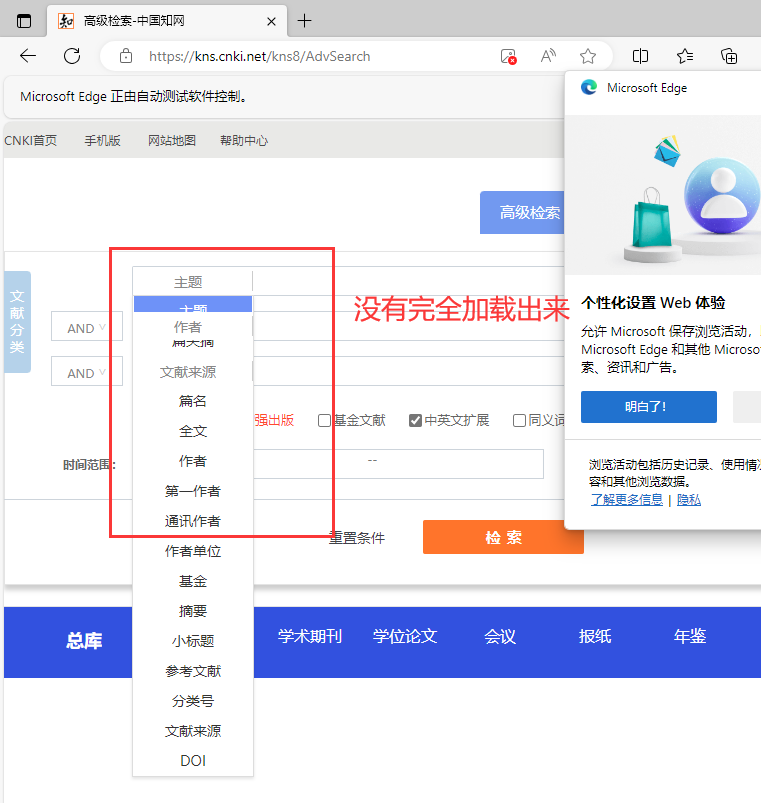
而且我还发现如果加载不完全的话,需要鼠标移动到下拉框那里,让下拉框完全加载。所以这里我使用了 selenium 中的 ActionChains 来模拟鼠标的操作
用 selenium 做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等
selenium 给我们提供了一个类来处理这类事件——ActionChains
还有一点需要注意的是:如果鼠标只是移到【关键词】,下拉框其实还是不能正确加载出来,最好是移动到下拉框的最底部或者关键词后面的元素,这里我移动到【通讯作者】
# 【通讯作者】定位
/html/body/div[2]/div/div[2]/div/div[2]/div[1]/div[1]/div[2]/ul/li[8]
li[data-val="RP"]
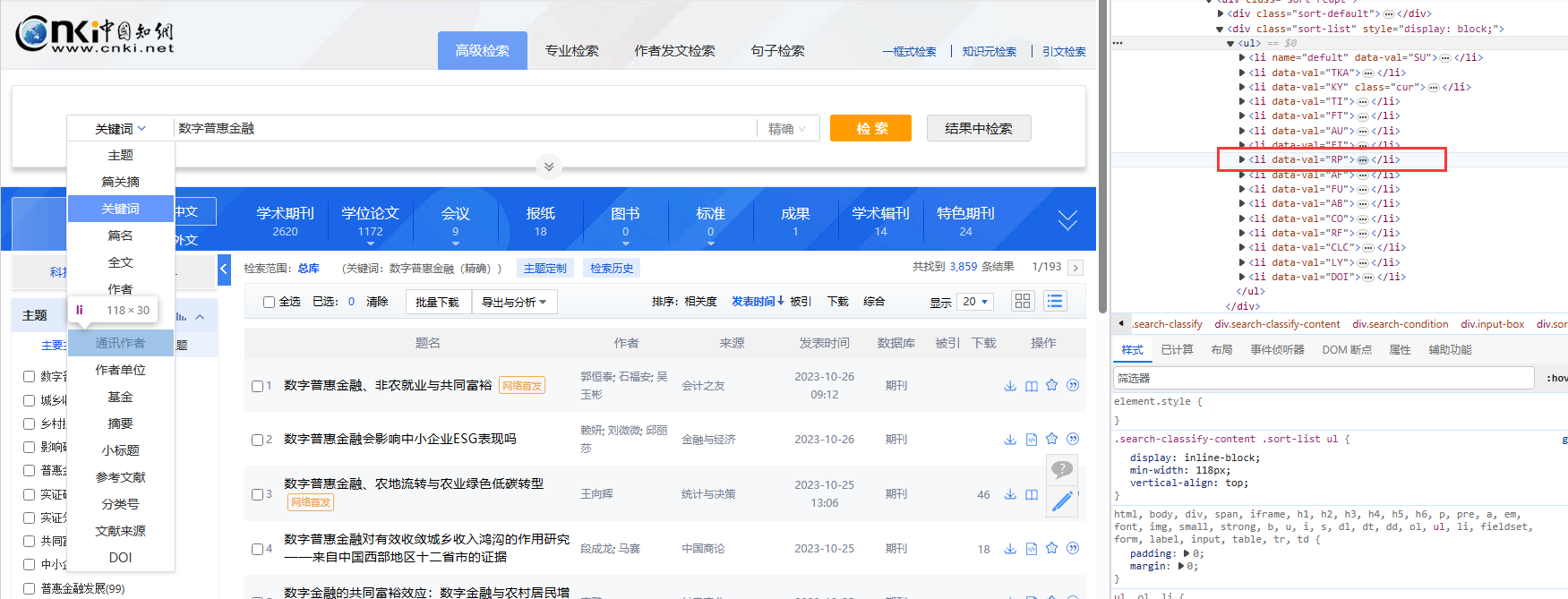
下拉框加载完成之后,定位到【关键词】再点击
# 鼠标移动到下拉框
ActionChains(driver).move_to_element(driver.find_element(By.CSS_SELECTOR, 'li[data-val="RP"]')).perform()
# 找到[关键词]选项并点击
WebDriverWait(driver, 100).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'li[data-val="KY"]'))).click()
定位出搜索框,传入我们要搜索的关键词
# 传入关键字
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, '''//*[@id="gradetxt"]/dd[1]/div[2]/input'''))
).send_keys(keyword)
# 点击搜索
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input"))
).click()
搜索结果出来之后定位【文献条数】,获取对应的条数(text 标签)
# 获取总文献数和页数
res_unm = WebDriverWait(driver, 100).until(EC.presence_of_element_located(
(By.XPATH, "/html/body/div[3]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em"))
).text
完整代码如下:
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.action_chains import ActionChains
def webserver():
# get直接返回,不再等待界面加载完成
desired_capabilities = DesiredCapabilities.EDGE
desired_capabilities["pageLoadStrategy"] = "none"
# 设置微软驱动器的环境
options = webdriver.EdgeOptions()
# 设置浏览器不加载图片,提高速度
options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 创建一个微软驱动器
driver = webdriver.Edge(options=options)
return driver
def open_page(driver, keyword):
# 打开页面,等待两秒
driver.get("https://kns.cnki.net/kns8/AdvSearch")
time.sleep(2)
# 修改属性,使下拉框显示
opt = driver.find_element(By.CSS_SELECTOR, 'div.sort-list') # 定位元素
driver.execute_script("arguments[0].setAttribute('style', 'display: block;')", opt) # 执行 js 脚本进行属性的修改;arguments[0]代表第一个属性
# 鼠标移动到下拉框中的[通讯作者]
ActionChains(driver).move_to_element(driver.find_element(By.CSS_SELECTOR, 'li[data-val="RP"]')).perform()
# 找到[关键词]选项并点击
WebDriverWait(driver, 100).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, 'li[data-val="KY"]'))).click()
# 传入关键字
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, '''//*[@id="gradetxt"]/dd[1]/div[2]/input'''))
).send_keys(keyword)
# 点击搜索
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input"))
).click()
# 点击切换中文文献
WebDriverWait(driver, 100).until(
EC.presence_of_element_located((By.XPATH, "/html/body/div[3]/div[1]/div/div/div/a[1]"))
).click()
# 获取总文献数和页数
res_unm = WebDriverWait(driver, 100).until(EC.presence_of_element_located(
(By.XPATH, "/html/body/div[3]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em"))
).text
# 去除千分位里的逗号
res_unm = int(res_unm.replace(",", ''))
page_unm = int(res_unm / 20) + 1
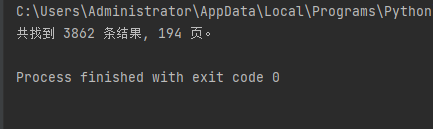
print(f"共找到 {res_unm} 条结果, {page_unm} 页。")
if __name__ == '__main__':
keyword = "数字普惠金融"
driver = webserver()
open_page(driver, keyword)
结果如下: