一、背景
拼接字符串根据某种规律拆分并转化为多行,只要拆分的主键和数据即可
二、预期结果
1、表A
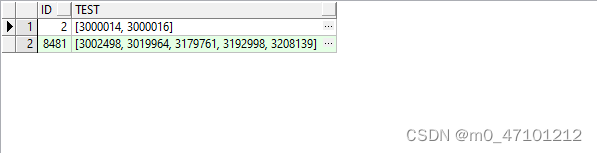
2、去除无效的字符,如'['、']'等
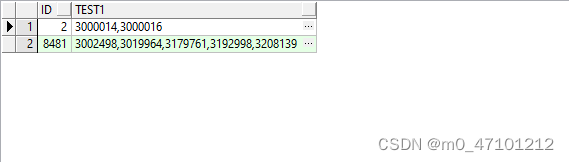
3、按逗号分割后结果

三、实现sql
1、去除无效的字符,如'['、']'等
SELECT ID,
replace(replace(replace(test /*替换的列*/, '[', ''), ']', ''),
' ',
'')
FROM table /*替换的表*/2、按逗号分割后结果
法一:
SELECT distinct ID,
REGEXP_SUBSTR(test1 /*替换拆分的列*/,
'[^,]+',
1,
LEVEL,
'i') as test2
FROM table /*替换表*/
CONNECT BY LEVEL <= LENGTH(test1 /*替换拆分的列*/) -
LENGTH(REPLACE(test1 /*替换拆分的列*/, ',', '')) + 1
order by ID法二:
SELECT distinct ID,
REGEXP_SUBSTR(test1 /*替换拆分的列*/,
'[^,]+',
1,
LEVEL,
'i') as test2
FROM table /*替换表*/
CONNECT BY LEVEL <= (regexp_count(test1 /*替换拆分的列*/, ',') + 1)
order by ID法三:数据量大时优先选用,效率高
SELECT ID,
substr(test1 /*替换拆分的列*/,
instr(test1 /*替换拆分的列*/, ',', 1, levels.lvl) + 1,
instr(test1 /*替换拆分的列*/, ',', 1, levels.lvl + 1) -
(instr(test1 /*替换拆分的列*/, ',', 1, levels.lvl) + 1)) as test1 /*替换拆分的列*/
FROM (SELECT id,
',' || test1 /*替换拆分的列*/
|| ',' AS test1 /*替换拆分的列*/,
length(test1 /*替换拆分的列*/) -
nvl(length(REPLACE(test1 /*替换拆分的列*/, ',')), 0) + 1 AS cnt
FROM table /*替换表*/
) a,
(SELECT rownum AS lvl
FROM (SELECT MAX(length(test1 /*替换拆分的列*/
|| ',') -
nvl(length(REPLACE(test1 /*替换拆分的列*/, ',')),
0)) max_len
FROM table /*替换表*/
)
CONNECT BY LEVEL <= max_len) levels
WHERE levels.lvl <= a.cnt
order by ID四、sql分析
1、REGEXP_SUBSTR 函数
Regexp_Substr(String,pattern,position,occurrence ,modifier )一共包含了五个参数:
- String:操作的字符串;
- pattern:正则表达式匹配规则,匹配到则返回;
- position:开始匹配的位置,默认当然是1;
- occurrence:标识第几个匹配组,默认为1 ;
- modifier:模式(‘i‘不区分大小写进行检索,‘c‘区分大小写进行检索。默认为‘c‘)。
说明:level oracle关键字,表示查询深度,用来实现层级查询
2、 REGEXP_COUNT 函数
REGEXP_COUNT ( source_char, pattern [, position [, match_param]])
REGEXP_COUNT 返回pattern 在source_char 串中出现的次数。如果未找到匹配,则函数返回0。position 变量告诉Oracle 在源串的什么位置开始搜索。在开始位置之后每出现一次模式,都会使计数结果增加1。
参数:
- source_char:指定要搜索的字符串;
- pattern:指定要搜索的正则表达式;
- position:要在源字符串中开始搜索的位置,缺省值为1;
- match_param:用于指定控制模式匹配行为的值,缺省值为NULL。
3、REPLACE 函数
把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次
Replace(old_text,start_num,num_chars,new_text)
=replace(要替换的字符串,开始位置,替换个数,新的文本)
举例:replace(test /*替换的列*/, '[', '')
附:多行转一行
//使用 distinct 去除重复项 listagg(distinct xx,',') within group(order by sort) //最后别忘记group by
总结
版权声明:除特别声明外,本站所有文章皆是本站原创,转载请以超链接形式注明出处!








