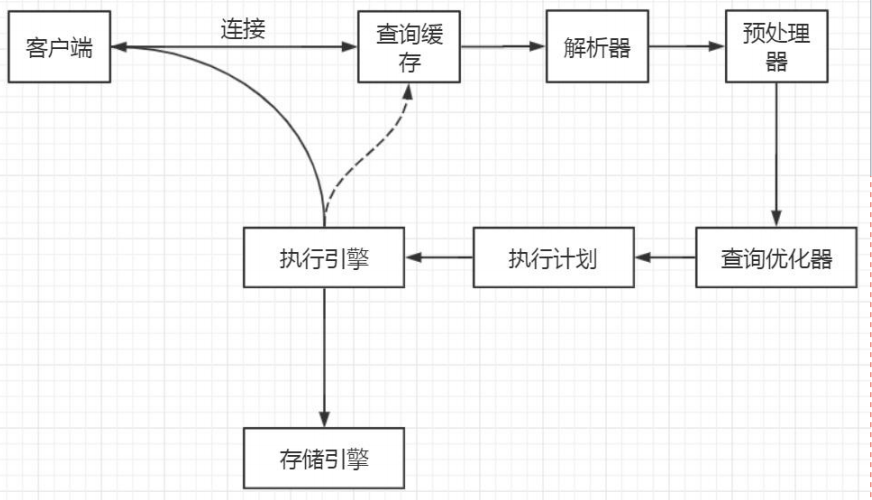
我们的程序或者工具要操作数据库,第一步要做什么事情? 跟数据库建立连接。
首先,MySQL必须要运行一个服务,监听默认的3306端口。在我们开发系统跟第三方对接的时候,必须要弄清楚的有两件事。
-
第一个就是通信协议,比如我们是用HTTP还是WebService还是TCP?
-
第二个是消息格式,比如我们用XML格式,还是JSON格式,还是定长格式?报文头长度多少,包含什么内容,每个字段的详细含义。
MySQL是支持多种通信协议的,可以使用同步/异步的方式,支持长连接/短连接。我们分别来看:
同步通信
同步通信依: 赖于被调用方,受限于被调用方的性能。也就是说,应用操作数据库,线程会阻塞,等待数据库的返回。一般只能做到一对一,很难做到一对多的通信。
异步通信
异步可以避免应用阻塞等待,但是不能节省SQL执行的时间。
如果异步存在并发,每一个SQL的执行都要单独建立一个连接,避免数据混乱。但是这样会给服务端带来巨大的压力(一个连接就会创建一个线程,线程间切换会占用大量CPU资源)。另外异步通信还带来了编码的复杂度,所以一般不建议使用。如果要异步,必须使用连接池,排队从连接池获取连接而不是创建新连接。
长连接与短连接
MySQL既支持短连接,也支持长连接。短连接就是操作完毕以后,马上close掉。长连接可以保持打开,减少服务端创建和释放连接的消耗,后面的程序访问的时候还可以使用这个连接。一般我们会在连接池中使用长连接。
保持长连接会消耗内存。长时间不活动的连接,MySQL服务器会断开。
showglobalvariableslike'wait_timeout';--非交互式超时时间,如JDBC程序
showglobalvariableslike'interactive_timeout';--交互式超时时间,如数据库工具
默认都是28800秒,8小时。
可以用showstatus命令:showglobalstatuslike'Thread%';
Threads_cached:缓存中的线程连接数。
Threads_connected:当前打开的连接数。
Threads_created:为处理连接创建的线程数。
Threads_running:非睡眠状态的连接数,通常指并发连接数。
MySQL支持哪些通信协议呢?
UnixSocket
比如我们在Linux服务器上,如果没有指定-h参数,它就用socket方式登录(省略了-S/var/lib/mysql/mysql.sock)。
它不用通过网络协议,也可以连接到MySQL的服务器,它需要用到服务器上的一个物理文件(/var/lib/mysql/mysql.sock)。
select @@socket;
TCP/IP 协议
我们的编程语言的连接模块都是用 TCP 协议连接到 MySQL 服务器的,比如 mysql-connector-java-x.x.xx.jar

2. 语法解析和预处理
为什么一条 SQL 语句能够被识别呢?假如我随便执行一个字符串 penyuyan,服务器报了一个 1064 的错, 它是怎么知道我输入的内容是错误的?
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the
right syntax to use near 'penyuyan' at line 1
这个就是 MySQL 的 Parser 解析器和 Preprocessor 预处理模块。 这一步主要做的事情是对语句基于 SQL 语法进行词法和语法分析和语义的解析。
词法解析
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词。 比如一个简单的 SQL 语句:
select name from user where id = 1;
它会打碎成 8 个符号,每个符号是什么类型,从哪里开始到哪里结束。
语法解析
语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL 定义的语法规则,根据 SQL 语句生成一个数据结构。这个数据结构我 们把它叫做解析树(select_lex)。
 任何数据库的中间件,比如Mycat,Sharding-JDBC(用到了DruidParser),都必须要有词法和语法分析功能,在市面上也有很多的开源的词法解析的工具(比如LEX,Yacc).
任何数据库的中间件,比如Mycat,Sharding-JDBC(用到了DruidParser),都必须要有词法和语法分析功能,在市面上也有很多的开源的词法解析的工具(比如LEX,Yacc).
预处理器
如果我写了一个词法和语法都正确的SQL,但是表名或者字段不存在,会在哪里报错?是在数据库的执行层还是解析器?比如:
select * from xxx;
解析器可以分析语法,但是它怎么知道数据库里面有什么表,表里面有什么字段呢?实际上还是在解析的时候报错,解析SQL的环节里面有个预处理器。 它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。预处理之后得到一个新的解析树。
3.查询优化(QueryOptimizer)与查询执行计划
得到解析树之后,是不是执行SQL语句了呢?这里我们有一个问题,一条SQL语句是不是只有一种执行方式?或者说数据库最终执行的SQL是不是就是我们发送的SQL?
这个答案是否定的。一条SQL语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是MySQL的查询优化器的模块(Optimizer)。 查询优化器的目的就是根据解析树生成不同的执行计划(ExecutionPlan),然后选择一种最优的执行计划,MySQL里面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种。
可以使用这个命令查看查询的开销:
showstatus like 'Last_query_cost';
优化器可以做什么?
举两个简单的例子:
1、当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表。 2、有多个索引可以使用的时候,选择哪个索引。
实际上,对于每一种数据库来说,优化器的模块都是必不可少的,他们通过复杂的算法实现尽可能优化查询效率的目标。 如果对于优化器的细节感兴趣,可以看看《数据库查询优化器的艺术-原理解析与SQL 性能优化》。
 但是优化器也不是万能的,并不是再垃圾的SQL语句都能自动优化,也不是每次都能选择到最优的执行计划,大家在编写SQL语句的时候还是要注意。
但是优化器也不是万能的,并不是再垃圾的SQL语句都能自动优化,也不是每次都能选择到最优的执行计划,大家在编写SQL语句的时候还是要注意。
优化器是怎么得到执行计划的?
首先我们要启用优化器的追踪(默认是关闭的):
SHOWVARIABLES LIKE 'optimizer_trace';
set optimizer_trace ='enabled=on';
注意开启这开关是会消耗性能的,因为它要把优化分析的结果写到表里面,所以不要轻易开启,或者查看完之后关闭它(改成off
接着我们执行一个SQL语句,优化器会生成执行计划:
select t.tcid from teacher t, teacher_contact tc wheret.tcid=tc.tcid;
这个时候优化器分析的过程已经记录到系统表里面了,我们可以查询:
select * from information_schema.optimizer_trace\G
它是一个JSON类型的数据,主要分成三部分,准备阶段、优化阶段和执行阶段。

expanded_query是优化后的SQL语句。
considered_execution_plans里面列出了所有的执行计划。
优化器得到的结果
优化器最终会把解析树变成一个查询执行计划,查询执行计划是一个数据结构。当然,这个执行计划是不是一定是最优的执行计划呢?不一定,因为MySQL也有可能覆盖不到所有的执行计划。
我们怎么查看MySQL的执行计划呢?比如多张表关联查询,先查询哪张表?在执行查询的时候可能用到哪些索引,实际上用到了什么索引?
MySQL提供了一个执行计划的工具。我们在SQL语句前面加上EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
*注意Explain的结果也不一定最终执行的方式。
4.存储引擎
得到执行计划以后,SQL语句是不是终于可以执行了? 问题又来了:
1、从逻辑的角度来说,我们的数据是放在哪里的,或者说放在一个什么结构里面?
2、执行计划在哪里执行?是谁去执行?
存储引擎基本介绍
我们先回答第一个问题:在关系型数据库里面,数据是放在什么结构里面的?
放在表Table里面的 我们可以把这个表理解成Excel电子表格的形式。所以我们的表在存储数据的同时,还要组织数据的存储结构,这个存储结构就是由我们的存储引擎决定的,所以我们也可以把存储引擎叫做表类型。
查看存储引擎
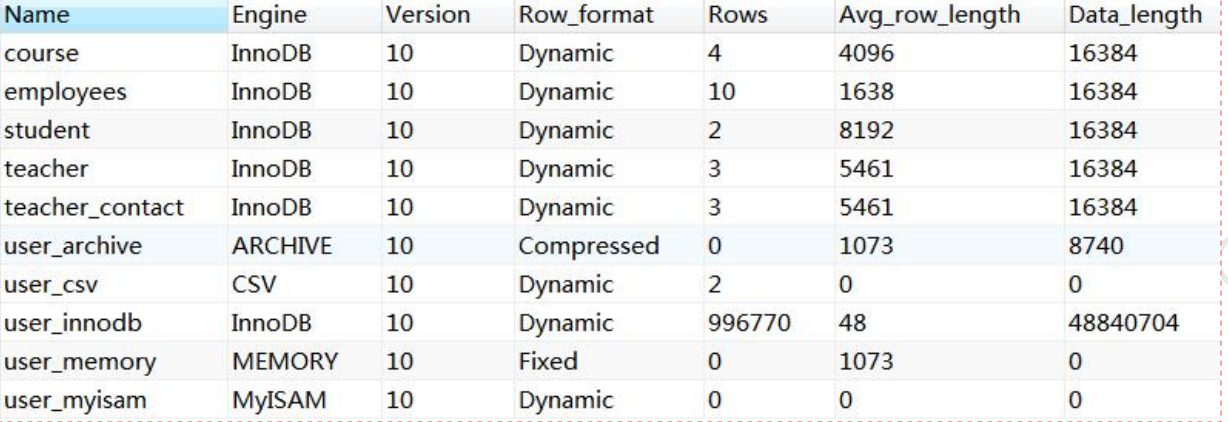
比如我们数据库里面已经存在的表,我们怎么查看它们的存储引擎呢?
show table status from `xxx`;
在MySQL里面,我们创建的每一张表都可以指定它的存储引擎,而不是一个数据库只能使用一个存储引擎。存储引擎的使用是以表为单位的。而且,创建表之后还可以修改存储引擎。
我们说一张表使用的存储引擎决定我们存储数据的结构,那在服务器上它们是怎么存储的呢?我们先要找到数据库存放数据的路径:
showvariableslike'datadir';
默认情况下,每个数据库有一个自己文件夹,任何一个存储引擎都有一个frm文件,这个是表结构定义文件。  不同的存储引擎存放数据的方式不一样,产生的文件也不一样,innodb是1个,memory没有,myisam是两个。
不同的存储引擎存放数据的方式不一样,产生的文件也不一样,innodb是1个,memory没有,myisam是两个。
这些存储引擎的差别在哪呢?
存储引擎比较
MyISAM和InnoDB是我们用得最多的两个存储引擎,在MySQL5.5版本之前,默认的存储引擎是MyISAM,它是MySQL自带的。我们创建表的时候不指定存储引擎,它就会使用MyISAM作为存储引擎.
MyISAM的前身是ISAM(IndexedSequentialAccessMethod:利用索引,顺序存取数据的方法).
5.5版本之后默认的存储引擎改成了InnoDB,它是第三方公司为MySQL开发的。为什么要改呢?最主要的原因还是InnoDB支持事务,支持行级别的锁,对于业务一致性要求高的场景来说更适合。
MyISAM
应用范围比较小。表级锁定限制了读/写的性能,因此在Web和数据仓库配置中,它通常用于只读或以读为主的工作。 特点:
-
支持表级别的锁(插入和更新会锁表)。不支持事务。
-
拥有较高的插入(insert)和查询(select)速度。
-
存储了表的行数(count速度更快)。
InnoDB
mysql5.7中的默认存储引擎。InnoDB是一个事务安全(与ACID兼容)的MySQL 存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁(不升级为更粗粒度的锁)和Oracle风格的一致非锁读提高了多用户并发性和性能。InnoDB将用户数据存储在聚集索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性, InnoDB还支持外键引用完整性约束。 特点:
-
支持事务,支持外键,因此数据的完整性、一致性更高。
-
支持行级别的锁和表级别的锁。
-
支持读写并发,写不阻塞读(MVCC)。
-
特殊的索引存放方式,可以减少IO,提升查询效率。
-
适合:经常更新的表,存在并发读写或者有事务处理的业务系统.
Memory
将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中快速访问。这个引擎以前被称为堆引擎。其使用案例正在减少;InnoDB及其缓冲池内存区域提供了一种通用、持久的方法来将大部分或所有数据保存在内存中,而ndbcluster为大型分布式数据集提供了快速的键值查找。 特点:
-
把数据放在内存里面,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失。只适合做临时表。
CSV
它的表实际上是带有逗号分隔值的文本文件。csv表允许以csv格式导入或转储数据,以便与读写相同格式的脚本和应用程序交换数据。因为csv表没有索引,所以通常在正常操作期间将数据保存在innodb表中,并且只在导入或导出阶段使用csv表。 特点: 特点:不允许空行,不支持索引。格式通用,可以直接编辑,适合在不同数据库之间导入导出。
Archive
这些紧凑的未索引的表用于存储和检索大量很少引用的历史、存档或安全审计信息。 特点:
-
不支持索引,不支持updatedelete。
如何选择存储引擎?
-
如果对数据一致性要求比较高,需要事务支持,可以选择InnoDB。
-
如果数据查询多更新少,对查询性能要求比较高,可以选择MyISAM。
-
如果需要一个用于查询的临时表,可以选择Memory。
5. 执行引擎
存储引擎分析完了,它是我们存储数据的形式,继续第二个问题,是谁使用执行计划去操作存储引擎呢?
这就是我们的执行引擎,它利用存储引擎提供的相应的API来完成操作。
为什么我们修改了表的存储引擎,操作方式不需要做任何改变?因为不同功能的存储引擎实现的API是相同的。








