一.背景
前段时间某医院由于群集服务器的兼容性问题需要将数据库由2012降至2008R2,所以决定把数据库暂时切换至镜像服务器,同时开启应用层面的DML缓存以便实现不停机降级。
由于2012备份无法直接还原至2008R2(MSSQL数据库还原 高>>低 不兼容),类似复制的其他功能也无法使用,OGG也不适合全库迁移,因此决定使用导入导出降级。
二.步骤
1.导出数据库对象架构(右键数据库--任务--生成脚本)

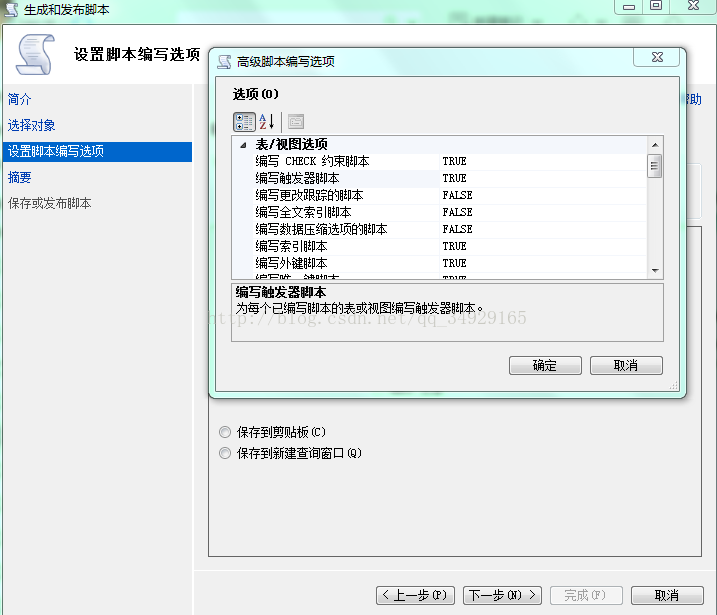
需要注意的是在高级脚本编写选项中需要选择好为2008R2版本生成的全库脚本,将索引触发器等选项一并选择true.
2.在目标2008R2库上执行上述脚本,观察报错,其中很多报错属于正常报错,原因是还没有数据。
3.需要选择生成所有登录名的选项,但是新创建的登录名和密码是随机的,因此需要提前拿到各个登录名的密码。同时由于
生成的脚本自动禁用登录名,因此需要为每个登录名解锁。
4.导出数据:
导出数据时不要选择视图,因为视图已经在步骤一中的脚本中建好,同时由于已经建好了表结构,导入工具会默认选择向已有表中插入数据。
导入数据用时较长,并且由于服务器资源瓶颈,因此设置每次导入50个表为好,具体个数取决于各个表的大小。分批次还有一个好处是可以看到每个表的导入进度,同时防止每次出错都重新导入,浪费大量时间。
三.总结
1.含identity自增列的表需要启动标识插入
如果相关的表较少可以在第一步的架构脚本中查询identity关键字,找出需要开启标识插入的表,如果很多则需要一个个勾选。
2.SqlServer排序规则错误,导致的数据无法导入,因此在建数据库时注意选择一致的排序规则。
排序规则分为:
实例级别的排序规则,影响新建数据库的默认排序规则,更改实例级别的排序规则需要删除所有数据库,停止实例后更改,之后再导回数据
数据库级别的排序规则,继承于实例的排序规则,可以个性化使用alter database <db_name> collate Chinese_PRC_CI_AS
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持寻技术。








