聚合管道
聚合框架是 MongoDB 中的一组分析工具,可以对一个或多个集合中的文档进行分析。
MongoDB 的聚合框架基于管道的概念:首先从集合中获取到输入,然后将输入的文档传递到一个或多个阶段,每个阶段都将之前阶段输出的内容作为输入,最终得到一个聚合结果作为输出。
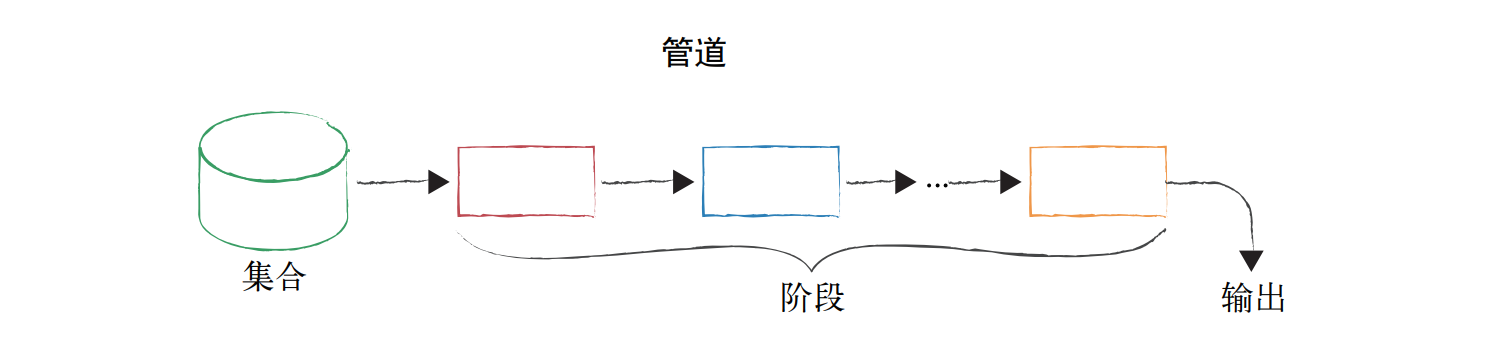
上面的图是一个比较宽泛的管道流程图。这里展示一个 MongoDB 聚合语句映射到管道之后的情况:
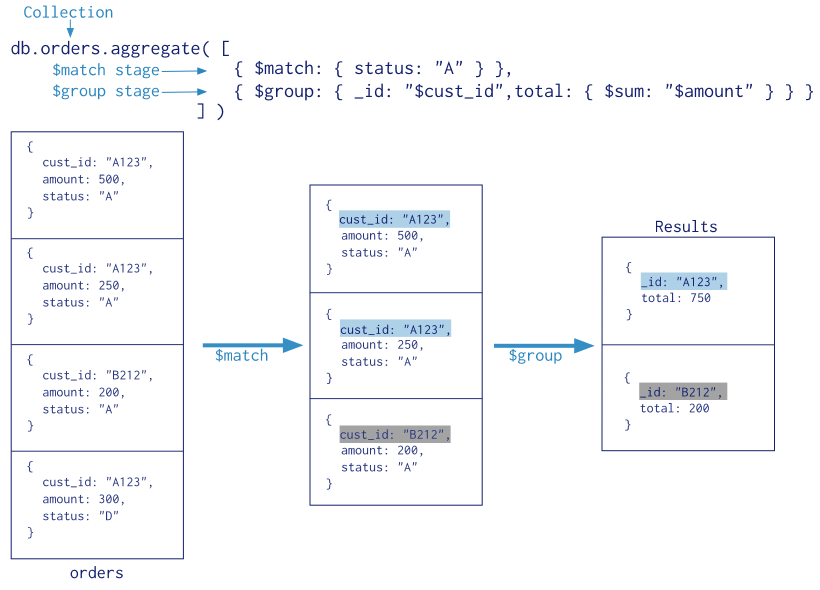
在这里可以看得出,aggregate([{}, {}]) 是一个聚合语句,在函数的数组中,每一个对象都是一个阶段,$match 应该就是一个筛选文档的阶段,$group 应该就是一个分组汇总的阶段。
管道阶段
使用聚合框架最重要的就是熟悉操作的语法,以及将这些语法构建成管道当中的阶段。
在 MongoDB 聚合框架中,每一个阶段都必须要规定一个特定的阶段运算符,这些阶段运算符表明了阶段的执行规则,可以到 官方文档 上查看更多、更详细的内容。
常见操作
最常见的操作应该是能与普通查询语句对应上的操作,如查询、投影、排序、跳过、限制等等。虽然这些在一个 find() 语句中就能实现。
最常使用的操作就是查询,也可以说是筛选、过滤,在聚合框架中使用 $match 来表明这是一个筛选文档的阶段。如下是其使用语法:
{ $match: { <query> } }第二个则是投影,这个阶段可以修改输入文档的结构,通常是重命名、增加、删除属性,也可以通过表达式创建计算结果以及嵌套文档。如下是其使用语法:
// <field>: <1 or true>
// <field>: <0 or false>
// <field>: <expression>
{ $project: { <specification(s)> } }
排序、跳过、限制都比较容易理解,实际上可以与 find() 结果的游标支持的函数做联系。如下是其使用语法:
// 排序
{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
// 跳过
{ $skip: <positive 64-bit integer> }
// 限制
{ $limit: <positive 64-bit integer> }上述 5 个阶段是最常用的阶段,在使用时需要注重它们的效率,一般会使用这样的顺序去构建管道:
- 通过筛选语句过滤指定集合,得到符合要求的文档列表;
- 如果排序非常重要,这一个阶段需要在过滤文档之后;
- 如果需要做分页功能,应该是先执行跳过的阶段,然后再到限制的阶段;
- 最后,执行投影阶段(进入投影阶段的文档应该尽量少)。
更多操作 - 投影
投影阶段一个比较大的作用就是,限制下一步的文档字段数量,也就是删除属性,如下是使用方式:
// 不返回 _id 字段
{ $project: { _id: 0 } }
// 不返回指定的 field 字段
{ $project: { <field>: 0 } }删除属性是黑名单的功能,投影阶段也支持白名单的功能,即返回列表内的字段,如下是使用方式:
// 返回指定的 field 字段
{ $project: { <field>: 1 } }前两个功能是比较好理解的,但投影阶段所能做的远不止如此,还有很多其他的功能(投影阶段支持大部分条件组),这里做个简单举例:
// 将 author 嵌套文档下 last 属性赋值给 lastName 属性
{ $project: { lastName: "$author.last" } }
// 上述的功能里,对于嵌套文档和内嵌数组返回的结果是不一样的,数组会继承下来
// 投影支持类似于三元运算的表达式
{ $project: { lastName: {
$cond: {
if: { $eq: [ "", "$author.last" ] },
then: "$$REMOVE",
else: "$author.last",
}
} } }更多操作 - 展开
在处理数组时,一个比较常见的操作是为数组中的每一个元素形成一个输出文档。
一个实际的例子就是,一件衣服在库存中有 S、M、L 三个尺寸,而这三个尺寸会存储在同一个数组字段当中,当我们聚合时想要将这一条文档展开成三个文档,一个尺寸对应一个文档。
// 原始文档
{
"clothesId": "123456",
"sizeList": ["S", "M", "L"]
}
// 展开后的文档
{
"clothesId": "123456",
"sizeList": "S"
}
{
"clothesId": "123456",
"sizeList": "M"
}
{
"clothesId": "123456",
"sizeList": "L"
}聚合过程中,展开阶段的语法是:
{ $unwind: <field path> }
// 上述衣服的例子中,可以用以下语句来展开
{ $unwind: "$sizeList" }
更多操作 - 分组
分组是聚合管道中举足轻重的一个阶段,这里的分组可以看作是 SQL 的 GOURP BY 语句,其能为聚合功能带来非常大的可能性。
分组阶段使用了 $group 运算符,支持使用一个键或多个键将输入的文档进行分组,其语法如下:
{
$group: {
// 分组的标识
_id: <expression>,
<field1>: { <accumulator1> : <expression1> },
...
}
}其中 _id 是必须的,可以简单指定分组的键,也可以使用条件组做处理后生成自定义键。
可选的 <field> 是分组后需要展示的键,并且可以指定条件组来决定它们的值是什么。
尤其是,MongoDB 提供了累加器可以实现复杂的功能,如求和、平均值、最大值、最小值等等。
这里有个对集合求和的例子,也是最简单的使用:
{
$group: {
// 对类型进行分组
_id: "type",
// 这里是求和,一个文档记作 1 个,即对同类型的文档进行计数
count: { $sum: 1 },
}
}更多操作 - 入库
顾名思义,入库需要作为管道中最后的阶段,将管道生成的文档写入集合中。
聚合框架提供了 $out 和 $merge 两个运算符标识入库阶段,其中 $merge 是在 4.2 版本中引入的。这两个操作符的语法如下:
// 指定数据库和集合,会直接覆盖
{ $out: { db: "<output-db>", coll: "<output-collection>" } }
// 配置更加丰富
{ $merge: {
// 指定数据库和集合
into: <collection> -or- { db: <db>, coll: <collection> },
// 确定唯一标识与集合中做匹配
on: <identifier field> -or- [ <identifier field1>, ...], // Optional
// 设定变量
let: <variables>, // Optional
// 如果标识存在时处理文档的方式
whenMatched: <replace|keepExisting|merge|fail|pipeline>, // Optional
// 如果标识不存在时处理文档的方式
whenNotMatched: <insert|discard|fail> // Optional
} }如果可以的话,建议使用 $merge 作为写入集合的首选方式,其功能更多。
当然,其真正的优势是,可以按照按需生成的物化视图(materialized view),在管道运行的阶段,输出到集合的内容会进行增量更新。
条件组累加器
在一些阶段操作中,MongoDB 支持使用累加器来增强聚合功能,这里说的累加器泛指求和、平均值、最大值、最小值等功能的操作符。
算术运算
这里的算术运算不是统称的四则运算,指的是与数学相关的运算,如平均值、求和等。
$avg 累加器用于计算平均值,通过是直接指定一个键名即可,使用 { $avg: "$keyName" } 这样的语法。
$sum 累加器用于计算指定键的和,也是直接指定一个键名即可,使用 { $sum: "$keyName" } 这样的语法。
最值运算
累加器支持的最值包括这些:最小值、最大值、最大的 n 个值。
最小值和最大值的理解都比较容易,使用也比较容易。最小值使用了 { $min: "$keyName" } 这样的语法,最大值使用了 { $max: "$keyName" } 这样的语法。
最大的 n 个值是在 5.2 版本新增的累加器,其作用是通过指定输入的键,得到这些键值中排序后最大的 n 个值,其语法如下:
{
$maxN: {
// 指定键名 input: "$score"
input: <expression>,
// 指定数量 n: 3
n: <expression>
}
}数组提取
这里的数组提取指的是提取数组中的某个元素,现在能支持到的就是提取出数组中的前 n 个元素、后 n 个元素。
在这里可以使用 $first、$firstN、$last、$lastN 这样的运算符,它们的语法分别如下:
{ $first: <expression> }
{
$firstN: {
input: <expression>,
n: <expression>
}
}
{ $last: <expression> }
{
$lastN: {
input: <expression>,
n: <expression>
}
}其他运算
除了上述的累加器,聚合框架还有非常多其他的累加器,这里简单列一下:
-
$accumulator: 返回自定义累加器函数的结果 -
$addToSet: 返回一个无重复值的数组 -
$bottom: 返回指定排序规则后最后 1 个元素 -
$bottomN: 返回指定排序规则后最后 n 个元素 -
$count: 返回文档的计数 -
$mergeObjects: 返回合并多个对象之后的结果 -
$push: 返回一个可以有重复值的数组 -
$stdDevPop: 返回输入值的总体标准差 -
$stdDevSamp: 返回输入值的样本标准差
这些累加器都有各自的用法,使用得当可实现非常强大的数据分析功能,完整的内容可以到 官方文档 上查看。