当涉及到网络通信和数据存储时,数据序列化一直都是一个重要的话题;特别是现在很多公司都在推行微服务,数据序列化更是重中之重,通常会选择使用 JSON 作为数据交换格式,且 JSON 已经成为业界的主流。但是 Google 这么大的公司使用的却是一种被称为 Protobuf 的数据交换格式,它是有什么优势吗?这篇文章介绍 Protobuf 的相关知识。

GitHub:https://github.com/protocolbuffers/protobuf
官方文档:https://protobuf.dev/overview/
Protobuf 介绍
Protobuf(Protocol Buffers)是由 Google 开发的一种轻量级、高效的数据交换格式,它被用于结构化数据的序列化、反序列化和传输。相比于 XML 和 JSON 等文本格式,Protobuf 具有更小的数据体积、更快的解析速度和更强的可扩展性。
Protobuf 的核心思想是使用协议(Protocol)来定义数据的结构和编码方式。使用 Protobuf,可以先定义数据的结构和各字段的类型、字段等信息,然后使用Protobuf提供的编译器生成对应的代码,用于序列化和反序列化数据。由于 Protobuf 是基于二进制编码的,因此可以在数据传输和存储中实现更高效的数据交换,同时也可以跨语言使用。
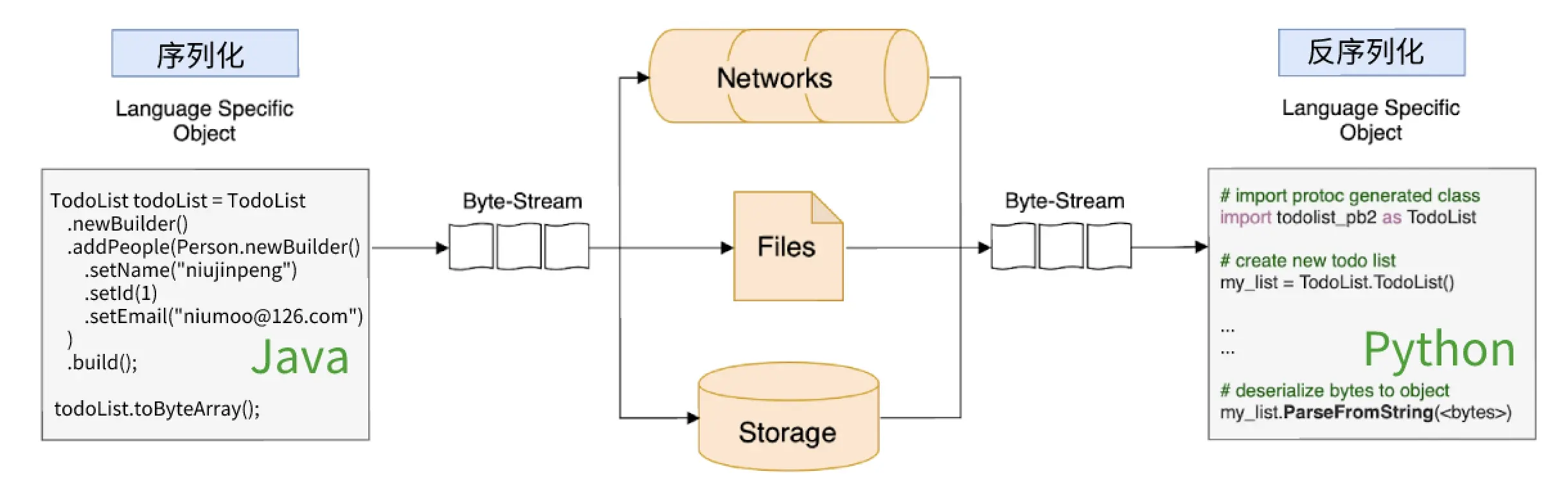
相比于 XML 和 JSON,Protobuf 有以下几个优势:
- 更小的数据量:Protobuf 的二进制编码通常比 XML 和 JSON 小 3-10 倍,因此在网络传输和存储数据时可以节省带宽和存储空间。
- 更快的序列化和反序列化速度:由于 Protobuf 使用二进制格式,所以序列化和反序列化速度比 XML 和 JSON 快得多。
- 跨语言:Protobuf 支持多种编程语言,可以使用不同的编程语言来编写客户端和服务端。这种跨语言的特性使得 Protobuf 受到很多开发者的欢迎(JSON 也是如此)。
- 易于维护可扩展:Protobuf 使用 .proto 文件定义数据模型和数据格式,这种文件比 XML 和 JSON 更容易阅读和维护,且可以在不破坏原有协议的基础上,轻松添加或删除字段,实现版本升级和兼容性。
编写 Protobuf
使用 Protobuf 的语言定义文件(.proto)可以定义要传输的信息的数据结构,可以包括各个字段的名称、类型等信息。同时也可以相互嵌套组合,构造出更加复杂的消息结构。
比如想要构造一个地址簿 AddressBook 信息结构。一个 AddressBook 可以包含多个人员 Person 信息,每个 Person 信息可以包含 id、name、email 信息,同时一个 Person 也可以包含多个电话号码信息 PhoneNumber,每个电话号码信息需要指定号码种类,如手机、家庭电话、工作电话等。
如果使用 Protobuf 编写定义文件如下:
// 文件:addressbook.proto
syntax = "proto3";
// 指定 protobuf 包名,防止有相同类名的 message 定义
package com.wdbyte.protobuf;
// 是否生成多个文件
option java_multiple_files = true;
// 生成的文件存放在哪个包下
option java_package = "com.wdbyte.tool.protos";
// 生成的类名,如果没有指定,会根据文件名自动转驼峰来命名
option java_outer_classname = "AddressBookProtos";
message Person {
// =1,=2 作为序列化后的二进制编码中的字段的唯一标签,也因此,1-15 比 16 会少一个字节,所以尽量使用 1-15 来指定常用字段。
optional int32 id = 1;
optional string name = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
optional string number = 1;
optional PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
}
message AddressBook {
repeated Person people = 1;
}
Protobuf 文件中的语法解释。
头部全局定义
-
syntax = "proto3";指定 Protobuf 版本为版本3(最新版本) -
package com.wdbyte.protobuf;指定 Protobuf 包名,防止有相同类名的message定义,这个包名是生成的类中所用到的一些信息的前缀,并非类所在包。 -
option java_multiple_files = true;是否生成多个文件。若false,则只会生成一个类,其他类以内部类形式提供。 -
option java_package =生成的类所在包。 -
option java_outer_classname生成的类名,若无,自动使用文件名进行驼峰转换来为类命名。
消息结构具体定义
message Person 定一个了一个 Person 类。
Person 类中的字段被 optional 修饰,被 optional 修饰说明字段可以不赋值。
- 修饰符
optional表示可选字段,可以不赋值。 - 修饰符
repeated表示数据重复多个,如数组,如 List。 - 修饰符
required表示必要字段,必须给值,否则会报错RuntimeException,但是在 Protobuf 版本 3 中被移除。即使在版本 2 中也应该慎用,因为一旦定义,很难更改。
字段类型定义
修饰符后面紧跟的是字段类型,如 int32 、string。常用的类型如下:
-
int32、int64、uint32、uint64:整数类型,包括有符号和无符号类型。 -
float、double:浮点数类型。 -
bool:布尔类型,只有两个值,true 和 false。 -
string:字符串类型。 -
bytes:二进制数据类型。 -
enum:枚举类型,枚举值可以是整数或字符串。 -
message:消息类型,可以嵌套其他消息类型,类似于结构体。
字段后面的 =1,=2 是作为序列化后的二进制编码中的字段的对应标签,因为 Protobuf 消息在序列化后是不包含字段信息的,只有对应的字段序号,所以节省了空间。也因此,1-15 比 16 会少一个字节,所以尽量使用 1-15 来指定常用字段。且一旦定义,不要随意更改,否则可能会对不上序列化信息。
编译 Protobuf
使用 Protobuf 提供的编译器,可以将 .proto 文件编译成各种语言的代码文件(如 Java、C++、Python 等)。
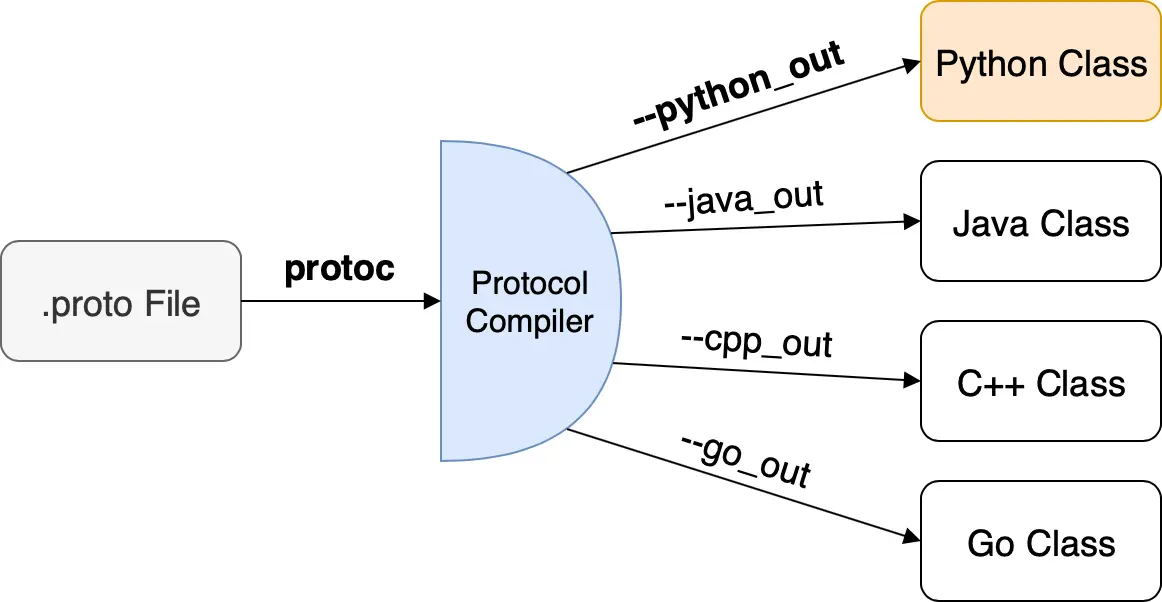
下载编译器:https://github.com/protocolbuffers/protobuf/releases/latest
安装完成后可以使用 protoc 命令编译 proto 文件,如编译示例中的 addressbook.proto.
protoc --java_out=./java ./resources/addressbook.proto
# --java_out 指定输出 java 格式文件,输出到 ./java 目录
# ./resources/addressbook.proto 为 proto 文件位置
生成后可以看到生产的类文件。
./
├── java
│ └── com
│ └── wdbyte
│ └── tool
│ ├── protos
│ │ ├── AddressBook.java
│ │ ├── AddressBookOrBuilder.java
│ │ ├── AddressBookProtos.java
│ │ ├── Person.java
│ │ ├── PersonOrBuilder.java
└── resources
├── addressbook.proto
使用 Protobuf
使用 Java 语言操作 Protobuf,首先需要引入 Protobuf 依赖。
Maven 依赖:
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.22.3</version>
</dependency>构造消息对象
// 直接构建
PhoneNumber phoneNumber1 = PhoneNumber.newBuilder().setNumber("18388888888").setType(PhoneType.HOME).build();
Person person1 = Person.newBuilder().setId(1).setName("www.wdbyte.com").setEmail("xxx@wdbyte.com").addPhones(phoneNumber1).build();
AddressBook addressBook1 = AddressBook.newBuilder().addPeople(person1).build();
System.out.println(addressBook1);
System.out.println("------------------");
// 链式构建
AddressBook addressBook2 = AddressBook
.newBuilder()
.addPeople(Person.newBuilder()
.setId(2)
.setName("www.wdbyte.com")
.setEmail("yyy@126.com")
.addPhones(PhoneNumber.newBuilder()
.setNumber("18388888888")
.setType(PhoneType.HOME)
)
)
.build();
System.out.println(addressBook2);
输出:
people {
id: 1
name: "www.wdbyte.com"
email: "xxx@wdbyte.com"
phones {
number: "18388888888"
type: HOME
}
}
------------------
people {
id: 2
name: "www.wdbyte.com"
email: "yyy@126.com"
phones {
number: "18388888888"
type: HOME
}
}
序列化、反序列化
序列化:将内存中的数据对象序列化为二进制数据,可以用于网络传输或存储等场景。
反序列化:将二进制数据反序列化成内存中的数据对象,可以用于数据处理和业务逻辑。
下面演示使用 Protobuf 进行字符数组和文件的序列化及反序列化过程。
package com.wdbyte.tool.protos;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/**
*
* @author www.wdbyte.com
*/
public class ProtobufTest2 {
public static void main(String[] args) throws IOException {
PhoneNumber phoneNumber1 = PhoneNumber.newBuilder().setNumber("18388888888").setType(PhoneType.HOME).build();
Person person1 = Person.newBuilder().setId(1).setName("www.wdbyte.com").setEmail("xxx@wdbyte.com").addPhones(phoneNumber1).build();
AddressBook addressBook1 = AddressBook.newBuilder().addPeople(person1).build();
// 序列化成字节数组
byte[] byteArray = addressBook1.toByteArray();
// 反序列化 - 字节数组转对象
AddressBook addressBook2 = AddressBook.parseFrom(byteArray);
System.out.println("字节数组反序列化:");
System.out.println(addressBook2);
// 序列化到文件
addressBook1.writeTo(new FileOutputStream("AddressBook1.txt"));
// 读取文件反序列化
AddressBook addressBook3 = AddressBook.parseFrom(new FileInputStream("AddressBook1.txt"));
System.out.println("文件读取反序列化:");
System.out.println(addressBook3);
}
}
输出:
字节数组反序列化:
people {
id: 1
name: "www.wdbyte.com"
email: "xxx@wdbyte.com"
phones {
number: "18388888888"
type: HOME
}
}
文件读取反序列化:
people {
id: 1
name: "www.wdbyte.com"
email: "xxx@wdbyte.com"
phones {
number: "18388888888"
type: HOME
}
}
Protobuf 为什么高效
在分析 Protobuf 高效之前,我们先确认一下 Protobuf 是否真的高效,下面将 Protobuf 与 JSON 进行对比,分别对比序列化和反序列化速度以及序列化后的存储占用大小。
测试工具:JMH,FastJSON,
测试对象:Protobuf 的 addressbook.proto,JSON 的普通 Java 类。
Maven 依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.7</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.33</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.33</version>
<scope>provided</scope>
</dependency>先编写与addressbook.proto 结构相同的 Java 类 AddressBookJava.java.
public class AddressBookJava {
List<PersonJava> personJavaList;
public static class PersonJava {
private int id;
private String name;
private String email;
private PhoneNumberJava phones;
// get...set...
}
public static class PhoneNumberJava {
private String number;
private PhoneTypeJava phoneTypeJava;
// get....set....
}
public enum PhoneTypeJava {
MOBILE, HOME, WORK;
}
public List<PersonJava> getPersonJavaList() {
return personJavaList;
}
public void setPersonJavaList(List<PersonJava> personJavaList) {
this.personJavaList = personJavaList;
}
}
序列化大小对比
分别在地址簿中添加 1000 个人员信息,输出序列化后的数组大小。
package com.wdbyte.tool.protos;
import java.io.IOException;
import java.util.ArrayList;
import com.alibaba.fastjson.JSON;
import com.wdbyte.tool.protos.AddressBook.Builder;
import com.wdbyte.tool.protos.AddressBookJava.PersonJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneNumberJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneTypeJava;
import com.wdbyte.tool.protos.Person.PhoneNumber;
import com.wdbyte.tool.protos.Person.PhoneType;
/**
* @author https://www.wdbyte.com
*/
public class ProtobufTest3 {
public static void main(String[] args) throws IOException {
AddressBookJava addressBookJava = createAddressBookJava(1000);
String jsonString = JSON.toJSONString(addressBookJava);
System.out.println("json string size:" + jsonString.length());
AddressBook addressBook = createAddressBook(1000);
byte[] addressBookByteArray = addressBook.toByteArray();
System.out.println("protobuf byte array size:" + addressBookByteArray.length);
}
public static AddressBook createAddressBook(int personCount) {
Builder builder = AddressBook.newBuilder();
for (int i = 0; i < personCount; i++) {
builder.addPeople(Person.newBuilder()
.setId(i)
.setName("www.wdbyte.com")
.setEmail("xxx@126.com")
.addPhones(PhoneNumber.newBuilder()
.setNumber("18333333333")
.setType(PhoneType.HOME)
)
);
}
return builder.build();
}
public static AddressBookJava createAddressBookJava(int personCount) {
AddressBookJava addressBookJava = new AddressBookJava();
addressBookJava.setPersonJavaList(new ArrayList<>());
for (int i = 0; i < personCount; i++) {
PersonJava personJava = new PersonJava();
personJava.setId(i);
personJava.setName("www.wdbyte.com");
personJava.setEmail("xxx@126.com");
PhoneNumberJava numberJava = new PhoneNumberJava();
numberJava.setNumber("18333333333");
numberJava.setPhoneTypeJava(PhoneTypeJava.HOME);
personJava.setPhones(numberJava);
addressBookJava.getPersonJavaList().add(personJava);
}
return addressBookJava;
}
}
输出:
json string size:108910
protobuf byte array size:50872
可见测试中 Protobuf 的序列化结果比 JSON 小了将近一倍左右。
序列化速度对比
使用 JMH 进行性能测试,分别测试 JSON 的序列化和反序列以及 Protobuf 的序列化和反序列化性能情况。每次测试前进行 3 次预热,每次 3 秒。接着进行 5 次测试,每次 3 秒,收集测试情况。
package com.wdbyte.tool.protos;
import java.util.ArrayList;
import java.util.concurrent.TimeUnit;
import com.alibaba.fastjson.JSON;
import com.google.protobuf.InvalidProtocolBufferException;
import com.wdbyte.tool.protos.AddressBook.Builder;
import com.wdbyte.tool.protos.AddressBookJava.PersonJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneNumberJava;
import com.wdbyte.tool.protos.AddressBookJava.PhoneTypeJava;
import com.wdbyte.tool.protos.Person.PhoneNumber;
import com.wdbyte.tool.protos.Person.PhoneType;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;
/**
* @author https://www.wdbyte.com
*/
@State(Scope.Thread)
@Fork(2)
@Warmup(iterations = 3, time = 3)
@Measurement(iterations = 5, time = 3)
@BenchmarkMode(Mode.Throughput) // Throughput:吞吐量,SampleTime:采样时间
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class ProtobufTest4 {
private AddressBookJava addressBookJava;
private AddressBook addressBook;
@Setup
public void init() {
addressBookJava = createAddressBookJava(1000);
addressBook = createAddressBook(1000);
}
@Benchmark
public AddressBookJava testJSON() {
// 转 JSON
String jsonString = JSON.toJSONString(addressBookJava);
// JSON 转对象
return JSON.parseObject(jsonString, AddressBookJava.class);
}
@Benchmark
public AddressBook testProtobuf() throws InvalidProtocolBufferException {
// 转 JSON
byte[] addressBookByteArray = addressBook.toByteArray();
// JSON 转对象
return AddressBook.parseFrom(addressBookByteArray);
}
public static AddressBook createAddressBook(int personCount) {
Builder builder = AddressBook.newBuilder();
for (int i = 0; i < personCount; i++) {
builder.addPeople(Person.newBuilder()
.setId(i)
.setName("www.wdbyte.com")
.setEmail("xxx@126.com")
.addPhones(PhoneNumber.newBuilder()
.setNumber("18333333333")
.setType(PhoneType.HOME)
)
);
}
return builder.build();
}
public static AddressBookJava createAddressBookJava(int personCount) {
AddressBookJava addressBookJava = new AddressBookJava();
addressBookJava.setPersonJavaList(new ArrayList<>());
for (int i = 0; i < personCount; i++) {
PersonJava personJava = new PersonJava();
personJava.setId(i);
personJava.setName("www.wdbyte.com");
personJava.setEmail("xxx@126.com");
PhoneNumberJava numberJava = new PhoneNumberJava();
numberJava.setNumber("18333333333");
numberJava.setPhoneTypeJava(PhoneTypeJava.HOME);
personJava.setPhones(numberJava);
addressBookJava.getPersonJavaList().add(personJava);
}
return addressBookJava;
}
}
JMH 吞吐量测试结果(Score 值越大吞吐量越高,性能越好):
Benchmark Mode Cnt Score Error Units
ProtobufTest3.testJSON thrpt 10 1.877 ± 0.287 ops/ms
ProtobufTest3.testProtobuf thrpt 10 2.813 ± 0.446 ops/ms
JMH 采样时间测试结果(Score 越小,采样时间越小,性能越好):
Benchmark Mode Cnt Score Error Units
ProtobufTest3.testJSON sample 53028 0.565 ± 0.005 ms/op
ProtobufTest3.testProtobuf sample 90413 0.332 ± 0.001 ms/op
从测试结果看,不管是吞吐量测试,还是采样时间测试,Protobuf 都优于 JSON。
为什么高效?
Protobuf 是如何实现这种高效紧凑的数据编码和解码的呢?
首先,Protobuf 使用二进制编码,会提高性能;其次 Protobuf 在将数据转换成二进制时,会对字段和类型重新编码,减少空间占用。它采用 TLV 格式来存储编码后的数据。TLV 也是就是 Tag-Length-Value ,是一种常见的编码方式,因为数据其实都是键值对形式,所以在 TAG 中会存储对应的字段和类型信息,Length 存储内容的长度,Value 存储具体的内容。

还记得上面定义结构体时每个字段都对应一个数字吗?如 =1,=2,=3.
message Person {
optional int32 id = 1;
optional string name = 2;
optional string email = 3;
}在序列化成二进制时候就是通过这个数字来标记对应的字段的,二进制中只存储这个数字,反序列化时通过这个数字找对应的字段。这也是上面为什么说尽量使用 1-15 范围内的数字,因为一旦超过 15,就需要多一个 bit 位来存储。
那么类型信息呢?比如 int32 怎么标记,因为类型个数有限,所以 Protobuf 规定了每个类型对应的二进制编码,比如 int32 对应二进制 000,string 对应二进制 010,这样就可以只用三个比特位存储类型信息。
这里只是举例描述大概思想,具体还有一些变化。
详情可以参考官方文档:https://protobuf.dev/programming-guides/encoding/
其次,Protobuf 还会采用一种变长编码的方式来存储数据。这种编码方式能够保证数据占用的空间最小化,从而减少了数据传输和存储的开销。具体来说,Protobuf 会将整数和浮点数等类型变换成一个或多个字节的形式,其中每个字节都包含了一部分数据信息和一部分标识符信息。这种编码方式可以在数据值比较小的情况下,只使用一个字节来存储数据,以此来提高编码效率。
最后,Protobuf 还可以通过采用压缩算法来减少数据传输的大小。比如 GZIP 算法能够将原始数据压缩成更小的二进制格式,从而在网络传输中能够节省带宽和传输时间。Protobuf 还提供了一些可选的压缩算法,如 zlib 和 snappy,这些算法在不同的场景下能够适应不同的压缩需求。
综上所述,Protobuf 在实现高效编码和解码的过程中,采用了多种优化方式,从而在实际应用中能够有效地提升数据传输和处理的效率。
总结
ProtoBuf 是一种轻量、高效的数据交换格式,它具有以下优点:
- 语言中立,可以支持多种编程语言;
- 数据结构清晰,易于维护和扩展;
- 二进制编码,数据体积小,传输效率高;
- 自动生成代码,开发效率高。
但是,ProtoBuf 也存在以下缺点:
- 学习成本较高,需要掌握其语法规则和使用方法;
- 需要先定义数据结构,然后才能对数据进行序列化和反序列化,增加了一定的开发成本;
- 由于二进制编码,可读性较差,这点不如 JSON 可以直接阅读。
总体来说,Protobuf 适合用于数据传输和存储等场景,能够提高数据传输效率和减少数据体积。但对于需要人类可读的数据,或需要实时修改的数据,或者对数据的传输效率和体积没那么在意的场景,选择更加通用的 JSON 未尝不是一个好的选择。
以上就是高效数据传输的秘密武器Protobuf的使用教程的详细内容,更多关于Protobuf数据传输的资料请关注寻技术其它相关文章!








