定制删除器
我们在上一篇文章中讲到了智能指针,相信大家都会有一个问题,智能指针该如何辨别我们的资源是用new int开辟的还是new int[]开辟的呢,要知道[]必须与delete[]匹配否则会有未知错误的,这个问题我们就交给定制删除器来解决:
int main()
{
shared_ptr<int> sp1(new int[10]);
shared_ptr<string> sp2(new string[10]);
return 0;
}比如上面的代码,一旦运行就会立即引发崩溃,这是因为shared_ptr默认的释放方式是delete而不是delete[]。
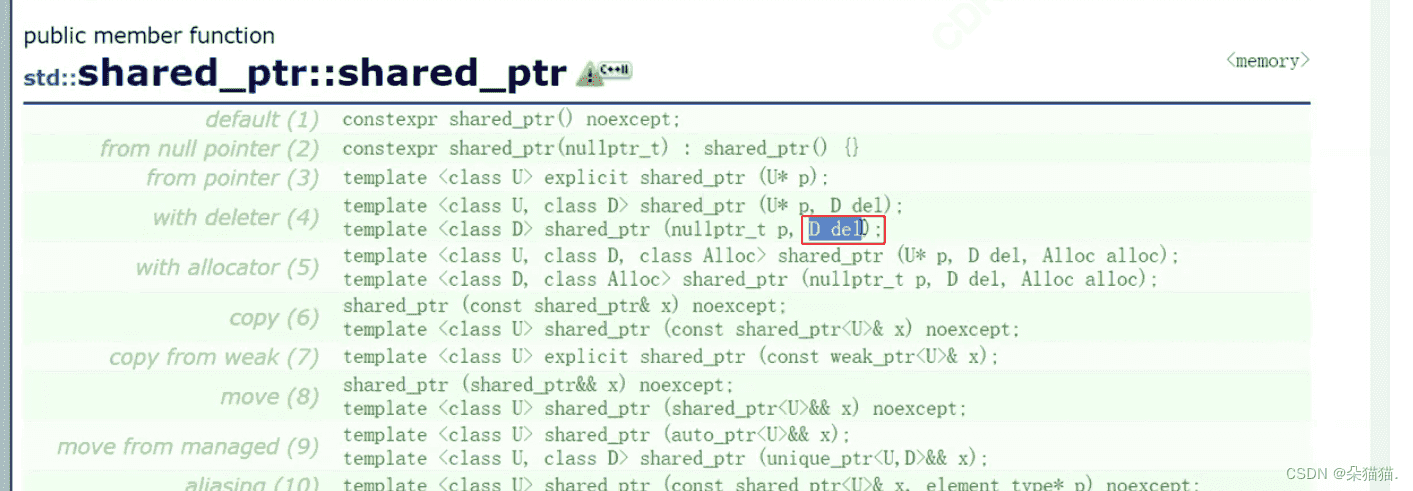
我们从文档中可以看到shared_ptr有一个模板参数是del,这个参数其实就是定制删除器,为了解决释放资源的问题。
template <class T>
struct DeleteArray
{
void operator()(const T* ptr)
{
delete[] ptr;
cout << "delete[]" <<ptr<< endl;
}
};
int main()
{
shared_ptr<int> sp1(new int[10],DeleteArray<int>());
shared_ptr<string> sp2(new string[10],DeleteArray<string>());
return 0;
}我们可以看到定制删除器非常简单,实际上就是一个仿函数,当我们将这个仿函数传给shared_ptr,shared_ptr会在它的构造函数中接收到这个仿函数,然后析构的时候就直接调用这个仿函数了。下面我们看看运行结果:
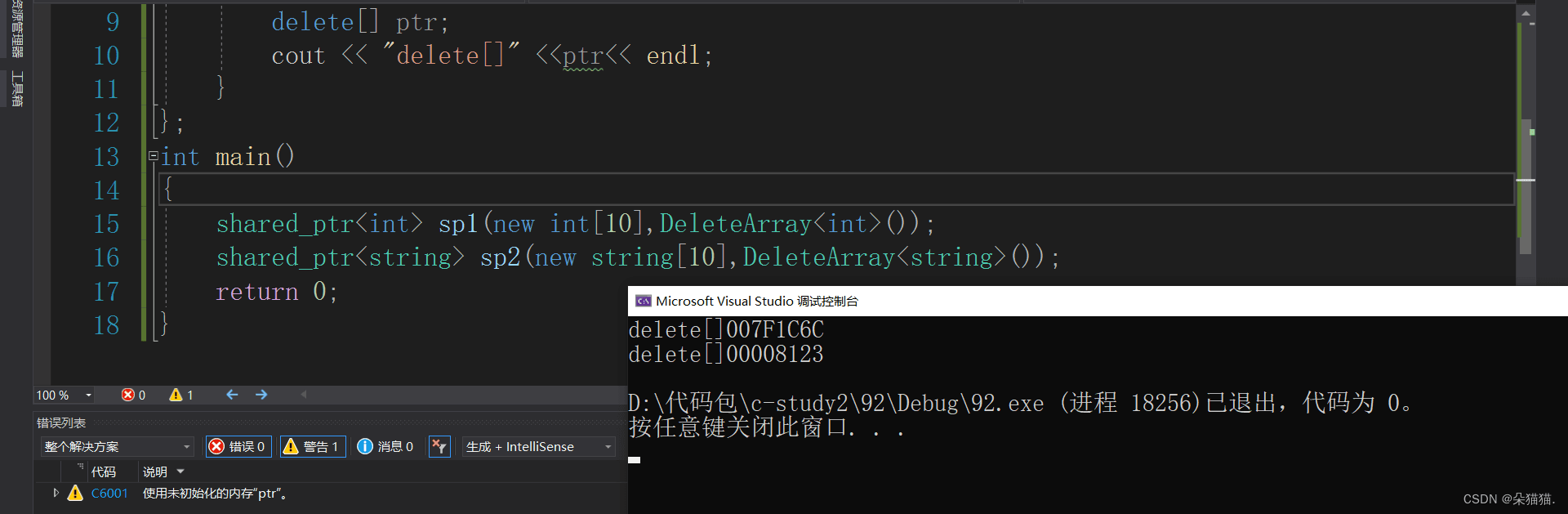
可以看到是能成功释放的,不再像之前那样由于new和delete不匹配导致崩溃。当然,这里既然是直接传给构造函数的,那么我们完全可以不用再写仿函数了,直接用lambda会更加的方便,如下所示:
int main()
{
shared_ptr<int> sp1(new int[10], [](const int* ptr)
{
delete[] ptr;
cout << "delete[] ptr :" << ptr << endl;
});
shared_ptr<string> sp2(new string[10], [](const string* ptr)
{
delete[] ptr;
cout << "delete[] ptr(string) :" << ptr << endl;
});
return 0;
}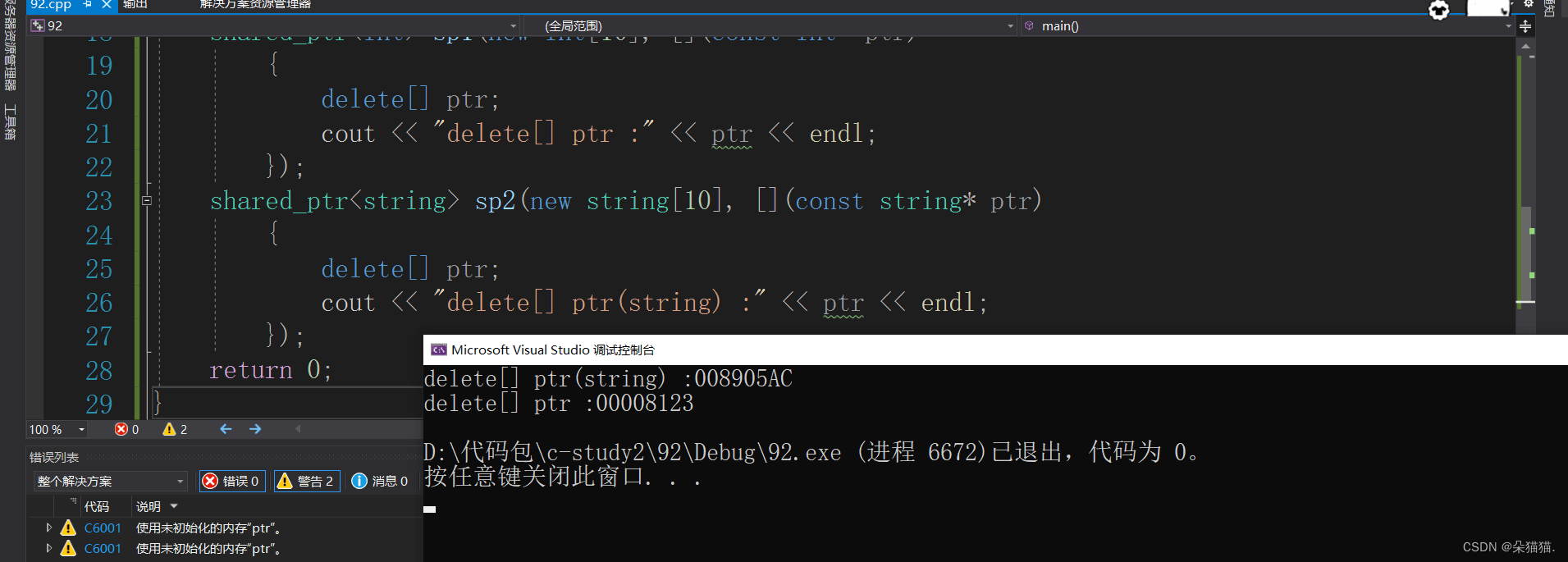
可以看到这样也是没有问题的如果不是要打印演示的话会比第一种方式更加的简洁,但是我们也说过lambda表达式的底层就是仿函数所以其实也差不了多少。当然我们不仅可以释放资源,还可以关闭文件:
shared_ptr<FILE> sp3(fopen("test", "w"), [](FILE* fp) { fclose(fp); });
下面我们也给自己的shared_ptr搞一个定制删除器模板:
首先我们自己是不能像库里面那样直接将定制删除器传给构造函数的,因为库里面的shared_ptr有好几个类,所以可以直接给构造函数加一个模板来传定制删除器。那么我们该如何解决呢?其实很容易因为我们就一个shared_ptr类,所以只需要给这个类多一个模板参数就可以了。
namespace sxy
{
template <class T>
struct Delete
{
void operator()(T* ptr)
{
delete ptr;
}
};
template <class T, class D = Delete<T>>
class shared_ptr
{
public:
//保存资源
shared_ptr(T* ptr = nullptr)
:_ptr(ptr)
, _pcount(new int(1))
, _pmtx(new mutex)
{
}
//拷贝构造
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
, _pmtx(sp._pmtx)
{
_pmtx->lock();
++(*_pcount);
_pmtx->unlock();
}
void Release()
{
bool flag = false;
_pmtx->lock();
if (--(*_pcount) == 0)
{
_del(_ptr);
delete _pcount;
flag = true;
}
_pmtx->unlock();
if (flag)
{
delete _pmtx;
}
}
//赋值重载
//..........
//释放资源
~shared_ptr()
{
Release();
}
//像指针一样
//..............
private:
T* _ptr;
int* _pcount;
mutex* _pmtx;
D _del;
};
}我们这里默认的是delete,当然也可以自己模板特化一个delete[],我们就不再演示了。下面我们先运行起来:
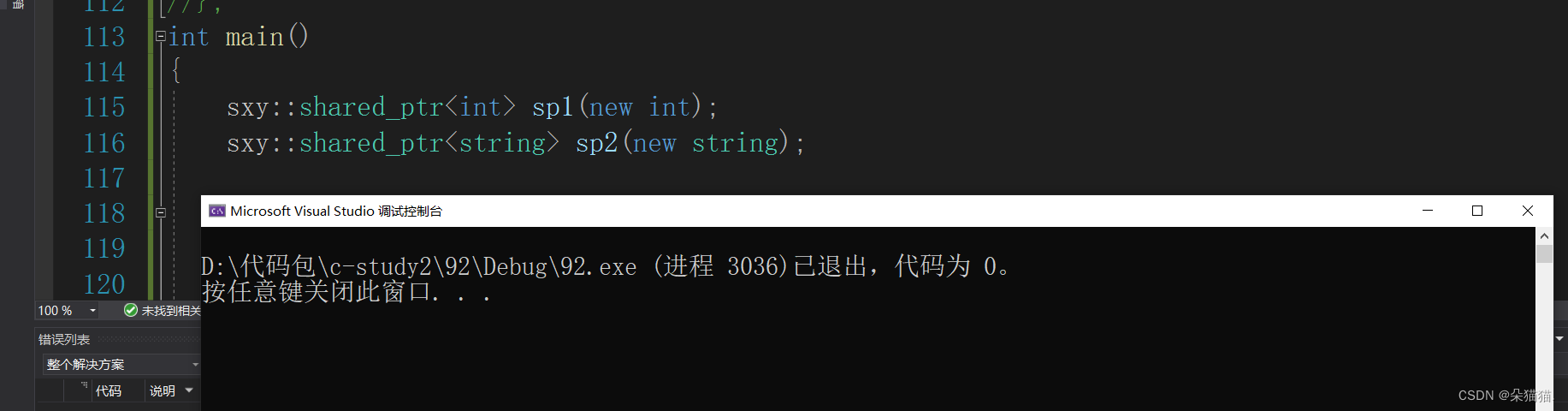
没有问题,我们再自己传一个[]的试一下:
int main()
{
sxy::shared_ptr<int,DeleteArray<int>> sp1(new int[10]);
sxy::shared_ptr<string,DeleteArray<string>> sp2(new string[10]);
return 0;
}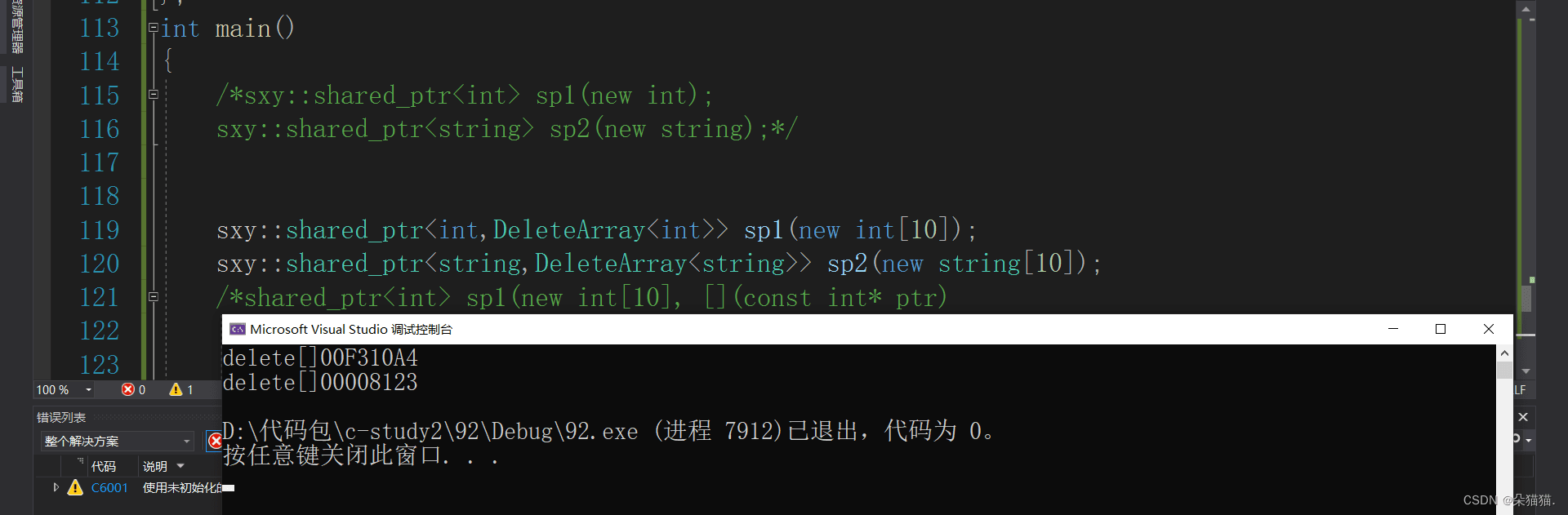
可以看到运行起来也是没有问题的,但是我们实现的定制删除器是不可以传lambda表达式的,这是因为lambda表达式无法作为一个参数类型。
注意:unique_ptr也和我们自己设计的删除器一样,都是不可以用lambda表达式的,这里大家可以自行去验证。
一、设计一个只能在堆上(或栈上)创建的类
我们在设计只能在堆上创建的类之前,先设计一个不能被拷贝的类,因为后面的类都会用到不能被拷贝的特点。
拷贝只会放生在两个场景中:拷贝构造函数以及赋值运算符重载,因此 想要让一个类禁止拷贝, 只需让该类不能调用拷贝构造函数以及赋值运算符重载即可。 C++98 将拷贝构造函数与赋值运算符重载只声明不定义,并且将其访问权限设置为私有即可。
class BanCopy
{
// ...
private:
BanCopy(const BanCopy& bc);
BanCopy& operator=(const BanCopy& bc);
//...
};原因:
1. 设置成私有:如果只声明没有设置成 private ,用户自己如果在类外定义了,就可以不 能禁止拷贝了
2. 只声明不定义:不定义是因为该函数根本不会调用,定义了其实也没有什么意义,不写 反而还简单,而且如果定义了就不会防止成员函数内部拷贝了。 C++11引入了delete关键字要禁用某个函数就更加的方便了:
C++11 扩展 delete 的用法, delete 除了释放 new 申请的资源外,如果在默认成员函数后跟上 =delete ,表示让编译器删除掉该默认成员函数。
class BanCopy
{
// ...
private:
BanCopy(const BanCopy& bc) = delete;
BanCopy& operator=(const BanCopy& bc) = delete;
//...
};下面我们思考如何实现只能在堆上创建的类,首先如果只能在堆上创建那么我们肯定是不能直接用构造函数创建对象的,所以要把构造函数私有,其次如果将一个堆上的对象拷贝给栈上的对象也不符合要求,所以拷贝构造肯定也要禁掉,下面我们实现一下:
class HeapOnly
{
public:
static HeapOnly* CreatObj()
{
return new HeapOnly;
}
void print()
{
cout << "print()" << endl;
}
private:
HeapOnly()
{}
HeapOnly(const HeapOnly&) = delete;
};
int main()
{
HeapOnly* hp = HeapOnly::CreatObj();
hp->print();
return 0;
}可以看到我们将构造函数设为私有,这样就不会有随意的对象被创建,只能通过我们的creat函数接收在堆上开辟的对象,注意我们的Creat接口一定是静态的,因为我们将构造封掉了没有这个类的对象,如果不设置为静态的那么谁来调用这个接口呢,其次我们还有禁掉拷贝构造,为了防止下面这种情况:
HeapOnly ht(*hp);
对于赋值重载来讲我们是没必要考虑的,因为赋值重载一定是针对于已经创建过的对象,我们将构造函数和拷贝构造禁掉就避免了栈对象的出现,被创建的一定是堆上的,那么堆上的对象赋值还是在堆上。
当然我们还有第二种只在堆上创建的类的思想:
class HeapOnly
{
public:
HeapOnly()
{}
void Destroy()
{
this->~HeapOnly();
}
private:
~HeapOnly()
{}
HeapOnly(const HeapOnly&) = delete;
};我们将析构函数设为私有,这样只要是栈上创建的对象都会编译报错,因为无法调用其析构函数,但是指针却可以正常的开辟空间,当我们将析构函数设为私有后那么该如何释放空间呢?只需要加一个成员函数,让这个成员函数调用类内的析构就可以了,这里不能直接调用析构需要用this指针指向一下否则会有编译错误。
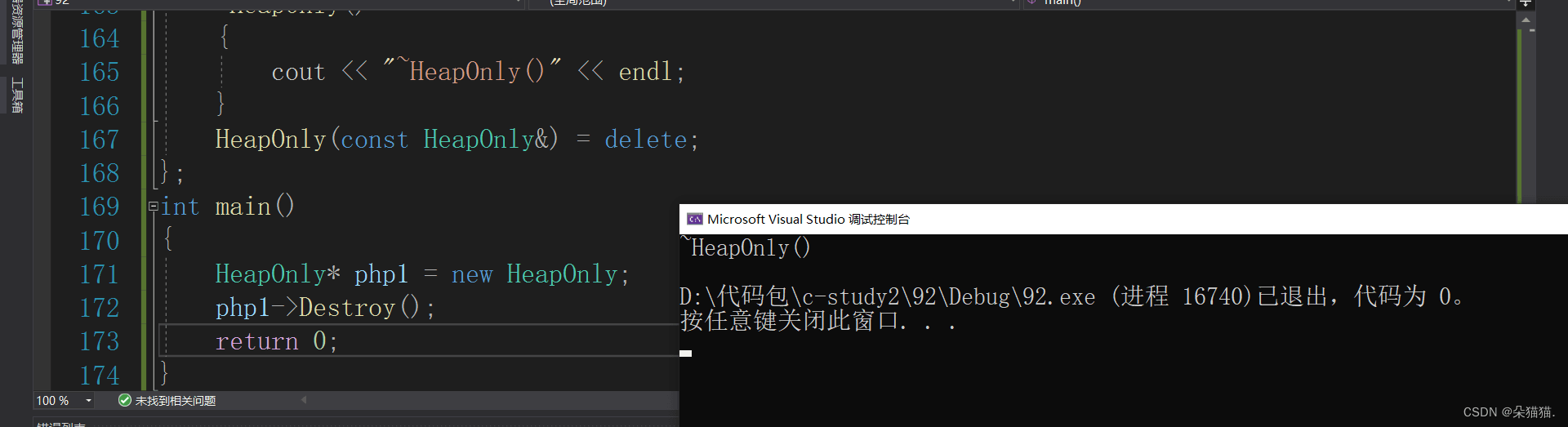
可以看到是没有问题的。
下面我们实现只在栈上创建的类:
只在栈上创建我们只需要禁掉operator new和operator delete以及禁止static变量即可。
class StackOnly
{
public:
static StackOnly CreatObj()
{
return StackOnly();
}
void print()
{
cout << "print()" << endl;
}
private:
StackOnly()
{}
};一旦我们将构造函数禁掉,那么static变量和stackOnly* = new都无法创建。当然这个类是封不死的对于下面这个情况:
static StackOnly st = StackOnly::CreatObj();
这也是这个类的缺陷,当然我们也可以直接禁掉operator new ,但是没必要因为我们禁掉析构后就无法调用new,毕竟new是需要构造函数的。
二、单例模式
设计模式:
设计模式( Design Pattern )是一套 被反复使用、多数人知晓的、经过分类的、代码设计经验的 总结 。
为什么会产生设计模式这样的东西呢?就像人类历史发展会产生兵法。最开始部落之间打 仗时都是人拼人的对砍。后来春秋战国时期,七国之间经常打仗,就发现打仗也是有 套路 的,后 来孙子就总结出了《孙子兵法》。孙子兵法也是类似。
使用设计模式的目的:为了代码可重用性、让代码更容易被他人理解、保证代码可靠性。 设计模 式使代码编写真正工程化;设计模式是软件工程的基石脉络,如同大厦的结构一样。
单例模式: 一个类只能创建一个对象,即单例模式,该模式可以保证系统中该类只有一个实例,并提供一个 访问它的全局访问点,该实例被所有程序模块共享 。比如在某个服务器程序中,该服务器的配置 信息存放在一个文件中,这些配置数据由一个单例对象统一读取,然后服务进程中的其他对象再 通过这个单例对象获取这些配置信息,这种方式简化了在复杂环境下的配置管理。
1.饿汉模式
我们先写出代码然后进行讲解:
#include <map>
class InfoSingleton
{
public:
static InfoSingleton& GetInstance()
{
return _sin;
}
void insert(string name,int salary)
{
_info[name] = salary;
}
void print()
{
for (auto& e : _info)
{
cout << e.first << " : " << e.second << endl;
}
cout << endl;
}
private:
InfoSingleton()
{}
InfoSingleton(const InfoSingleton&) = delete;
InfoSingleton& operator=(const InfoSingleton&) = delete;
map<string, int> _info;
static InfoSingleton _sin;
};首先单例模式是只能创建一个对象,所以我们必须将构造函数设为私有,上面的场景是一个工资管理表用map存放,既然只有一个类我们就直接加了一个私有静态成员,这个成员就是我们唯一使用的类,注意我们还需要将这个静态成员在类外初始化:
InfoSingleton InfoSingleton::_sin;
然后我们设计一个getinstance的接口可以返回这个私有对象,注意返回的是引用因为只有一个类不能产生拷贝。insert和print接口是为了演示所以设计出来了,然后我们要将拷贝构造和赋值都禁掉,还是那个原因只有一个对象。接下来我们运行起来看看:
int main()
{
InfoSingleton::GetInstance().insert("张三", 20);
InfoSingleton& sl = InfoSingleton::GetInstance();
sl.insert("李四", 200);
sl.insert("王五", 600);
sl.insert("赵六", 3100);
sl.print();
return 0;
}上面的代码中我们给出了两种拿到这个类的唯一对象的方法,一种是利用静态成员函数的特性直接使用,另一个是引用接收,下面我们看看结果:
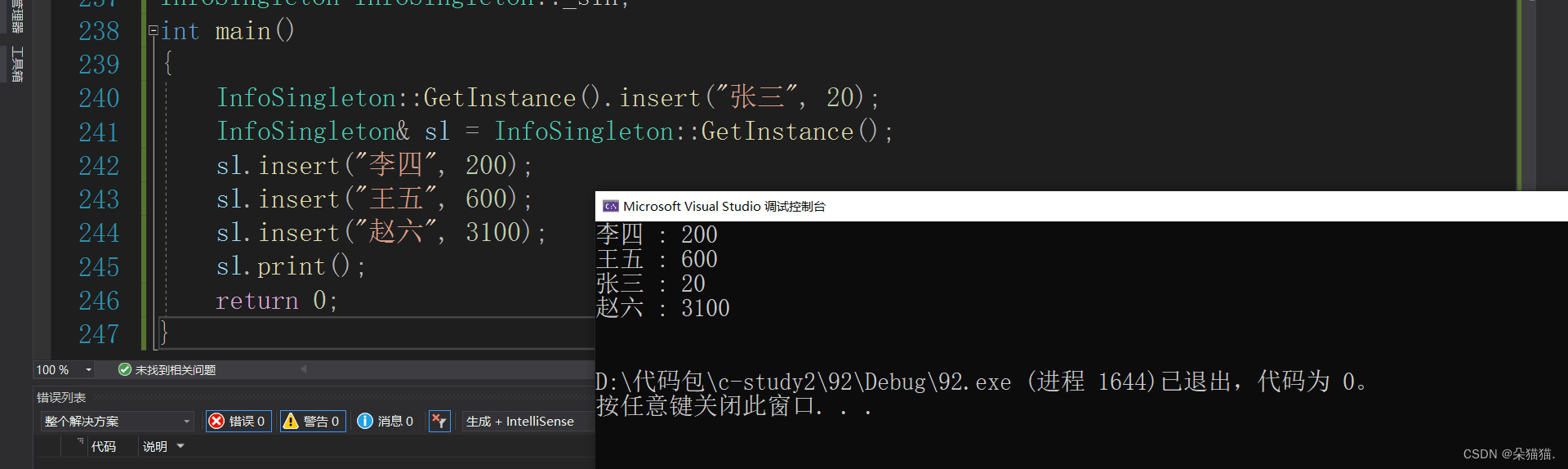
结果也是没有问题的,下面我们说一说饿汉模式的缺点:
首先因为静态成员变量的原因,我们的类会在main函数开始之前就创建对象,这么做就会有一些缺点,比如:单例对象初始化的时候数据太多,会导致启动慢。2.多个单例类如果有初始化依赖关系的话,那么饿汉模式是无法保证哪个类先初始化的(比如:A和B都是单例类,我们要求B先初始化然后再初始化A,但是饿汉模式是无法控制顺序的)。
2.懒汉模式
懒汉模式和饿汉模式的区别在于,懒汉模式是等需要用到对象的时候再创建,下面我们写一下代码:
class InfoSingleton
{
public:
static InfoSingleton* GetInstance()
{
//第一次获取单例对象的时候创建对象
if (_psin == nullptr)
{
return new InfoSingleton;
}
return _psin;
}
void insert(string name, int salary)
{
_info[name] = salary;
}
void print()
{
for (auto& e : _info)
{
cout << e.first << " : " << e.second << endl;
}
cout << endl;
}
private:
InfoSingleton()
{}
InfoSingleton(const InfoSingleton&) = delete;
InfoSingleton& operator=(const InfoSingleton&) = delete;
map<string, int> _info;
static InfoSingleton* _psin;
};
InfoSingleton* InfoSingleton::_psin = nullptr;我们可以看到饿汉模式和懒汉模式代码上的区别是:
饿汉模式用的是静态成员变量,懒汉模式用的静态成员变量指针,并且懒汉模式只有第一次获取单列对象的时候才创建对象,这就解决了刚刚饿汉模式启动的时候初始化数据太多导致启动慢的问题,并且懒汉模式如果在有依赖关系的情况下是可以控制先初始化某个类再初始化某个类的。
不知道大家有没有发现,我们现在写的懒汉模式是有一个很明显的问题的,那就是如果是多线程的情况下第一次获取单例对象的时候有可能多new了对象,面对这个情况我们可以直接加锁解决问题。
//懒汉模式
class InfoSingleton
{
public:
static InfoSingleton* GetInstance()
{
//第一次获取单例对象的时候创建对象
//lock_guard<mutex> lock(_mtx);
if (_psin == nullptr)
{
lock_guard<mutex> lock(_mtx);
if (_psin == nullptr)
{
return new InfoSingleton;
}
}
return _psin;
}
private:
InfoSingleton()
{}
InfoSingleton(const InfoSingleton&) = delete;
InfoSingleton& operator=(const InfoSingleton&) = delete;
map<string, int> _info;
static InfoSingleton* _psin;
static mutex _mtx;
};
InfoSingleton* InfoSingleton::_psin = nullptr;
mutex InfoSingleton::_mtx;首先我们定义锁的时候必须是静态的,这是因为getinstance这个函数就是静态的,这个函数里是无法调用普通成员函数的,只能调用静态成员函数,并且我们的锁只需要保护第一次来判断是否需要创建对象的情况,如果写成下面这样的代码就会造成资源浪费:
static InfoSingleton* GetInstance()
{
lock_guard<mutex> lock(_mtx);
if (_psin == nullptr)
{
return new InfoSingleton;
}
return _psin;
}为什么会造成资源浪费呢?因为第一次创建后后面的几次我们只需要返回这个对象的指针,这个时候是不需要加锁的,而像上面的代码我们即使已经创建过一次对象了进来后还是要加锁解锁消耗资源,这就造成了资源的浪费,所以我们多做一个判断就能解决这个问题。注意:饿汉模式是没有这个线程安全的问题的,因为饿汉模式在main函数之前就创建好对象了,main函数之前是不会有两个线程去创建对象的。
当然一般情况下我们的单例对象是不考虑释放的,不过如果需要释放该如何释放呢?其实和创建的时候一样,写一个静态的接口即可,代码如下:
static void DelInstance()
{
lock_guard<mutex> lock(_mtx);
if (_psin != nullptr)
{
delete _psin;
_psin = nullptr;
}
}当然也有人想到如果有些人就是忘记手动释放资源那就麻烦了,所以又出现了一个自动的释放资源的方法:
class GC
{
public:
~GC()
{
if (_psin)
{
cout << "~GC()" << endl;
DelInstance();
}
}
};GC是这个类对象的内部类,这个类的析构函数就是如果我们没有手动释放单例类的资源,那么GC这个对象出了作用域会自动帮我们进行销毁。
下面我们将程序运行起来看看能否释放:

上面是我们自己手动释放后,GC就没有帮我们释放,下面我们再看看自己不手动释放GC是否会帮我们释放:

所以我们总结一下,GC有下面两个好处:
可以手动调用主动回收,也可以让它在程序结束时自动回收。
当然下面还有一种更简单的懒汉模式的实现方法:
class InfoSingleton
{
public:
static InfoSingleton& GetInstance()
{
static InfoSingleton sin;
return sin;
}
void insert(string name, int salary)
{
_info[name] = salary;
}
void print()
{
for (auto& e : _info)
{
cout << e.first << " : " << e.second << endl;
}
cout << endl;
}
private:
InfoSingleton()
{}
InfoSingleton(const InfoSingleton&) = delete;
InfoSingleton& operator=(const InfoSingleton&) = delete;
map<string, int> _info;
};为什么这种方法也被称为懒汉模式呢?这是因为getinstance这个函数内部定义的静态变量sin是一个局部静态变量,一个局部的静态成员变量在初始化的时候是在main函数后初始化,所以和我们new的效果一样,并且还不用加锁保护。这个方式就利用了一个知识点:静态的局部变量是在main函数之后才创建初始化的。但是对于这样的写法有一个点需要注意:

在C++11之前,上面红框的部分是不能保证sin的初始化是线程安全的,在C++11之后,可以保证sin的初始化是线程安全的。
总结
设计模式中最重要的就是单例模式了,这个模式在面试中是高频考点大家一定要学会。






