一、前言:
目前,大模型的一个热门应用方向text2sql它可以帮助用户快速生成想要查询的SQL语句。那对于用户来说,大部分简单的sql都是正确的,但对于一些复杂逻辑来说,需要用户在产出SQL的基础上进行简单修改,Text2SQL应用主要还是帮助用户去解决开发时间,减少开发成本。
Text to SQL: 简称Text2SQl,是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。
它的目的可以简单概括为:“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
二、背景应用:
目前大家对T2S的做法大致分为两种,
- 一种是用现有的大模型来直接生成,例如ChatGPT、GPT-4模型,但是对于一些公司来说,数据是属于保密资产,这种方式相当于将自己公司的数据信息透漏给大模型,属于数据泄露行为;
- 另一种方式是利用开源的大模型做finetune,比如chatglm2-6b来做微调,这个也是目前我们在做的,同时开源的数据集也有很多,简单罗列如下:
| 数据集 | 数据集介绍 |
|---|---|
| WikiSQL | WikiSQL是一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。 WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。 虽然数据规模大,SQL语法却非常简单;适合做NL2SQL任务入门。 |
| Spider | 耶鲁大学在2018年新提出的一个大规模的NL2SQL(Text-to-SQL)数据集。 该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。 涉及的SQL语法最全面,是目前难度最大的NL2SQL数据集。 |
| Cspider | CSpider是Spider的中文版,西湖大学出品。 |
| Sparc | 耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。 SParC是一个跨域上下文语义分析的数据集,是Spider任务的上下文交互版本。SParC由4298个对话(12k+个单独的问题,每个对话平均4-5个子问题,由14个耶鲁学生标注)组成,这些问题通过用户与138个领域的200个复杂数据库进行交互获得。 |
| CHASE | 微软亚研院和北航、西安交大联合提出的首个大规模上下文依赖的Text-to-SQL中文数据集。 内容分为CHASE-C和CHASE-T两部分,CHASE-C从头标注实现,CHASE-T将Sparc从英文翻译为中; 相比以往数据集,CHASE大幅增加了hard类型的数据规模,减少了上下文独立样本的数据量,弥补了Text2SQL多轮交互任务中文数据集的空白。 |
三、Text2SQL使用:
我们在Text2SQL上面的应用主要包括两个阶段,第一阶段是利用LLM理解你的请求,通过请求去生成结构化的SQL;下一个阶段是在生成的SQL上自动化的查询数据库,返回结果,然后利用LLM对结果生成总结,提供分析。
3.1 第一阶段:
利用LLM理解文本信息,生成SQL,目前通过spider数据集来评测,GPT家族还是笑傲群雄。但是这里我们如果只借助GPT来做的话,就会出现之前说的数据隐私问题。
这里我们通过两部分来提升LLM对文本的理解,生成更符合我们要求的结果。
1. 构建数据信息表的schema,利用LLM生成embedding
由于我们从离线评测效果来看,开源模型chatglm2-6b直接生成的SQL和GPT对比,还是有比较大的差距,所以无法直接使用。这里我们根据用户描述的text,让预训练的chatglm2-6b生成embedding,通过embedding检索的方式,选出top1数据表,这个过程属于先验过滤阶段。
数据表的schema设计非常重要,需要描述清楚这个表它的主体信息以及表中重要字段和字段含义。
例:
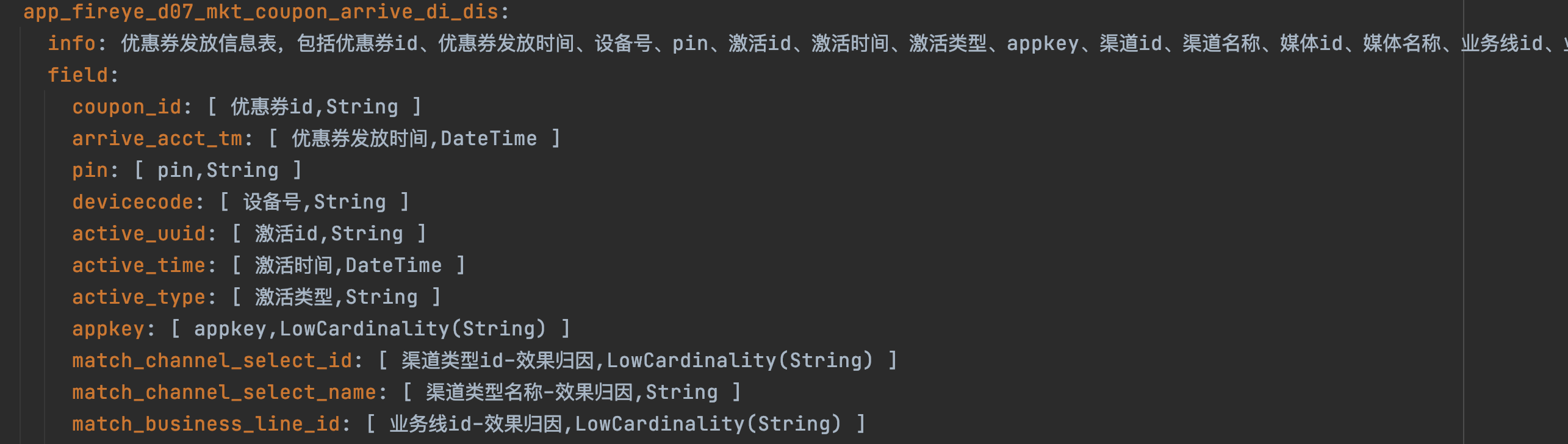
数据表的embedding可以提前计算保存,这样利用后期检索效率。
2. prompt构建,生成SQL
这部分我认为最重要的还是如何去合理构建prompt,让LLM去理解你的真实意图,生成标准的SQL。
一是prompt的开头需要定义构建,二是prompt整体结构以及结构中数据表的信息也需要涵盖进去,这里我们prompt的开头首先定义LLM的工作目的是生成SQL,通过我们根据第一部分返回的top1数据表,解析数据表中的信息,加入到prompt中,以此来构建完成的prompt。
1)开头prompt定义:

2)数据表prompt定义:

3)In-context-prompt:如果想强化prompt,可以增加一些正样本“问答”式的结构,让LLM去学习理解,最终生成更理想的结果

prompt的构建对最终结果的影响非常重要,构建一个完美的prompt可能已经成功了一半。
通过以上的prompt构建,我们就可以给LLM让模型生成最终的SQL结果。

3.2 第二阶段:
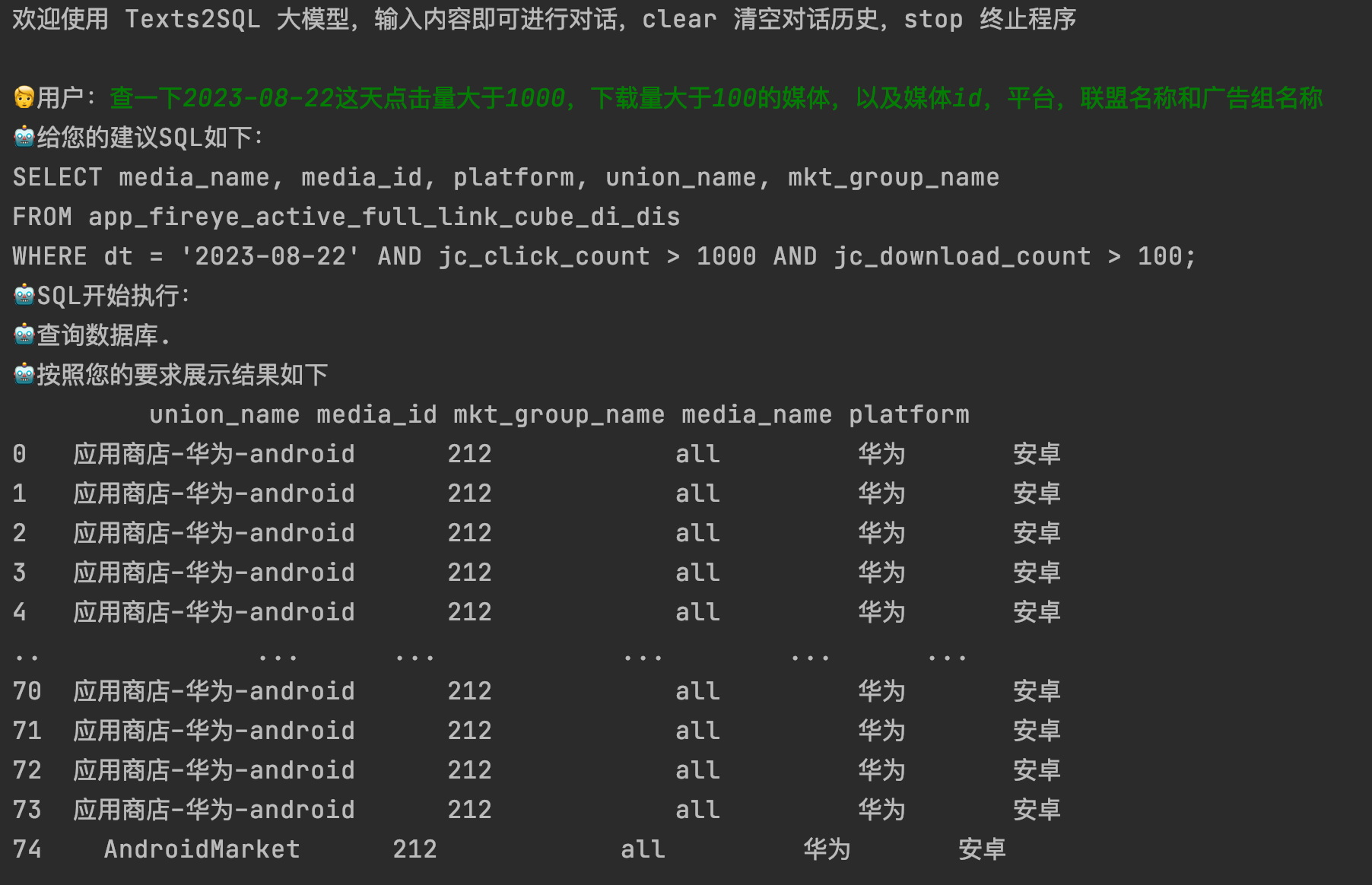
其实很多场景上一阶段生成SQL就已经达到我们想要的结果,但这里我们还想进一步根据SQL生成最终的数据,所以需要连接数据库,SQL运行返回结果。这里我们通过连接集团CK数据库,以接口的形式进行部署,我们在运行SQL的时候,其实就是调用接口,这样方便简洁,对接口返回的结果进行结构化的输出就可以。
通过接口访问结构化输出:

四、结果:
以上就是目前我们根据LLM来生成SQL,同时让SQL自动运行产生结果。前期我们利用GPT模型去跑通整个pipeline,同时生成一些训练数据集,来提供chatglm2-6b微调,后期我们还会对产出的结果进行数据分析,这个阶段也是利用LLM来完成,通过这种方式给用户一些指导性的意见或总结。
以下是整个pipeline的流程:
作者:京东零售 郑少强
来源:京东云开发者社区 转载请注明来源








